第三届研究生羽毛球赛纪实
2005年12月18日, 我们天文系羽毛球队在南大体育馆奋力拼杀一天, 获得出人意料的好成绩--亚军.
熟悉我们情况的对我们出线不会很意外, 不熟悉的对我们的亚军头衔一定以为是捡来的. 殊不知, 有了戴海浪的崛起, 我们的实力已不可与一年前同日而语. 我们的每一场比赛都是凭硬本事拿下的, 虽然在抽签分组的时候运气比较好. 下面一场场道来.
小组循环赛, 对人文(中文, 历史, 政治+法学院?), 数学, 教育
在我感觉, 这里是悬念最大的. 很有可能形成天文, 人文, 数学各赢两场的局面, 然后比胜负关系, 净胜局, 甚至净胜球.
早上九点, 开始对人文, 男一单戴海浪对人文的彭林(音), 彭林的杀球凶狠, 屡屡得分, 当第一局打到16:16, 我着实为戴捏着一把汗. 而这种最后一分, 实在只能是各有一半的机会. 我们得到了这一半. 好在我们戴的体力好, 第二局对方已明显体力不支, 顺利拿下. 第二场女单, 姜冰对人文的女二号(女一号还没过来, 后来来了, 在另一个场地远看到她和教育的女生对打时的矫健, 实在了的. 不幸的是中途严重受伤了, 祝她早日康复. 这也告诉我们打球之前必须先热身), 当听到对方说手下留情的时候, 就知道结果了. 第三场男双, 戴和我, 没什么印象, 赢了. 3:0. 但想想还是惊险, 如果彭林避开戴, 我是打不赢他的, 而对方女单一号没迟到, 我们说不定就输了. 戴海浪很强, 分组之后就料定他们是我们的最主要的对手.
接着对教育, 我们抽空看了他们在对面场上和数学的比赛, 他们的特点是女生强男生弱. 一个长头发的女生跑动非常灵活. 于是我们采用最保险的布阵: 男一, 戴海浪; 女单, 姜冰; 男双, 戴海浪和我; 混双, 彭志欣和姜冰; 男二, 我. 因为我们已经看出对方男生肯定打不过戴和我, 所以女单和混双就可以打得很轻松, 赢了最好, 不赢我们也可以以3:2取胜. 第一场没有悬念, 2:0, 第二场不敌, 0:2, 第三场也没有悬念, 2:0, 第四场让老彭打得很郁闷, 感觉能赢的, 可就是老丢分, 主要是平时配合少了, 不够默契, 还有一着急, 失误较多, 0:2. 第五场开始我打得叫辛苦, 主要是对手不怕杀球, 还有就是我的力量不足, 杀球速度慢, 威胁小. 后来我干脆好球也不杀了, 直接摆明了拉一个后场, 调一个网前, 对方男单比较胖, 不愿意跑动, 一般调网前的时候他就让球落地了, 2:0. 顺利赢球. 3:2.
中间空闲吃午餐, 盒饭.
数学和教育相似, 只是女生更强, 蒋永薪无人能敌; 男生也更强, 还好他们的男一号据戴的估计也最多和我差不多. 我们打法只能是和刚才一样了, 只换了混双由邵琅上. 但是现在既要考虑出线问题, 还要考虑出线后的对手. 我们半区另两支出线队伍打到那个时候多半确定是电子和计算机出线, 而电子的情形和我们差不多, 到时候胜负难料, 计算机女生很强, 可男生很少见抛头露面, 据戴的估计(此人平时场上混得频繁, 对每个球员都很了解, 这次的预测几乎没有失误, 值得赞)男一我也能打得过. 那么我们就愿意打计算机一些. 于是我们得在比赛过程中看那边赛场上的情况, 预测我们以小组第二出线, 对那边小组第一出线的计算机. 而这个过程中我们还必须保证不能被淘汰. 所以我们不时的去计算净胜局, 净胜球. 当计算前两场净胜球的时候, 发现我们对80, 数学76, 相差如此之近. 比赛开始, 戴的第一场轻松拿下, 2:0. 姜的女单轻松输掉(没办法), 0:2. 男双在上周五我们打过的, 心中有底, 不会输. 不过不是轻松, 2:0. 混双彭和姜上场, 不敌, 0:2. 然后我和对方一单(后来才知道是一单), 第一局全力打, 没想到对方被动拉球很有力道, 都能拉到我的后场; 也没想到原来他是用了很大的劲, 在我和他多拍过程之后后就没有体力了. 第一局赢了. 第二局输. 第三局, 当我确定我们输了也铁定出线之后, 输了. 这样就2:3输了.
计算净胜局:
数学: 教育3:0(=3) + 人文2:3(=-1) + 天文3:2(=1) = 3
人文: 教育3:0(=3) + 天文0:3(=-3) + 数学3:2(=1) = 1
天文: 教育3:2(=1) + 数学2:3(=-1) + 人文3:0(=3) = 3
教育: 人文0:3(=-3)+ 数学0:3(=-3) + 天文2:3(=-1)= -7
所以数学和天文出线, 在胜负关系上天文负于数学, 所以数学小组第一, 天文小组第二. 而那边也确实计算机小组第一, 电子第二. 顺利完成了战术目标.
和计算机的打法依然不变. 曾经他们的男一过来说他的状态奇好, 还没有输过. 害得我以为他要硬碰戴海浪呢. 戴估计得准, 说他不会碰. 不过我们有恃无恐, 排阵戴, 徐, 戴邹, 姜彭, 邹. 果然戴遇到的是男二, 轻松拿下, 2:0., 女单, 0:2. 男双赢了, 还是没有印象, 2:0. 混双输了, 0:2 (不怪队员不努力, 实在敌人太强大, 平时看见计算机的女生都是和男生一起打的, 动作, 力道都很好). 我遇到的是对方的男一, 还好, 戴先给了信心, 打的不慌不忙, 大比分第一局拿下; 第二局也在大比分领先的情况下, 居然被追不少. 调整心态, 终于拿到赛点, 打破了对方的防线, 然后顺利过关. 2:3.
吵着中午没吃饱的戴吵着要吃饭, 在比赛过程中就把晚饭买来了(感谢队员兼后勤部长GRB和铁杆啦啦队源starhunter), 我还在打的时候他们就开饭了, 看的我眼馋啊.
没想到另一边数学赢了! 下面出线的四支队伍(天文, 数学, 建研, 商院)抽签决定对手. 运气又是向着我们的: 和数学争夺决赛权. 接受他们的祝贺:)
我们出戴, 徐, 戴邹, 姜彭, 邹. 为节省时间, 男单和女单同时进行. 几乎是重复小组赛的故事, 戴赢了. 徐晓燕带伤上场, 精神可嘉, 0:2. 男双和混双同时进行. 男双第一局, 我们赢了, 交换场地..., 嗯? 人呢? 他们弃权了, 男二单也弃权了. 不战而胜. 至少是亚军了, 我们欢呼!
然后观看打满五场的建研所和商学院的精彩比赛. 最后建研胜出. 虽然我们以逸待劳, 实在实力悬殊. 为节约时间, 三场单打同时进行. 由于我们可以拼一拼建研的女生, 而单打我不能敌, 所以排阵戴, 姜, 戴邹, 姜邹, 邵. 而打两场双打的我就可以在场边做啦啦队了. 邵琅的最先结束, 0:2, 他也以重在参与的精神对待这局比赛, 没有压力. 姜冰的压力比较大, 只有她和戴至少赢得一场比赛, 我们才有可能继续下面的双打. 而戴还从来没有赢过他的"师父"何炽立, 赢的可能性还是姜冰这边大一些. 在刚开局的时候, 一度进行着激烈的争夺发球的拉锯战, 可是后来姜的体力透支, 而对手看样子体力很好, 这种拉锯没持续多久就渐落下风, 从而在后场失球较多. 在战术方面, 由于对手是用左手, 所以我们希望强拉对手右手后场(也就是她的反手后场)取得优势, 但经验颇足的建研女一很快调整站位, 站到更靠她的右手半场, 而姜在继续拉对方的反手后场的时候频频出线. 再后来想到了改杀另半场, 可是也角度太大不好控制, 加上最初对拉耗体力过多而控制不住, 导致在另一边出边线. 最后0:2惜败. 戴和何的单打持续最久, 这是一场体力和技术的硬拼, 发球权也是在双方 频繁交换. 奈何何的技术和动作都高一筹 (戴的击球前的转体, 击球点的选择, 移动步伐还有不少提高的余地(虽然我的更差, 评论一下还是可以的吧)), 分别以8:15, 5:15(如果没记错的话)败北.
2005.12.20
附:
2004年比赛日记
标 题: 羽毛球赛失利分析
时 间: Mon Dec 6 14:30:05 2004
昨天的院系羽毛球赛我们在小组循环赛以1:3告负, 属于意料之内, 但也使我们想做黑马的
希望泡汤.
五个队中商学院, 建筑研究所, 化院的实力确是比我们强很多. 不过运用田忌之术也不是
完全没有赢的希望, 我们只能寄希望于此. 所幸他们完全有把握, 先填出场名单并不怕我
们看, 我们也就把田忌术用到了极点. 可惜仍然不能赢, 只能叹学艺不精.
第一场对中美中心, 他们是神秘的, 不过也就意味着没有叱咤风云的人物, 否则经常出没
羽毛球场的人岂有不只之理? 我们采用保守的布阵, 这是这次比赛赢的可能性最大的一场
, 要尽量保证不能输, 于是男单, 女单, 男双, 混双, 男二分别是彭,徐,戴邹,姜邹,戴.
3:1获胜(0:2,2:0,2:0,2:0). 很有可能男单的胜利是他们中美的唯一一次赢球.
第二场对化院, 我们出邵,姜,戴邹,姜邹,戴, 0:3落败(0:2,0:2,1:2).
第三场对商院, 我们出戴,徐,戴邹,姜邵,邹, 1:3落败(0:2,0:2,2:1,0:2). 他们的男一算
是秘密武器, 分组初始只知道他们女生在我们组无敌, 后来也耳闻男生也打得很好, 可终
究没有见过, 原来他一年多没打过. 看到第一场他和建研的比赛, 我们就有底了(知道打不
过), 但是我们还是只能力拼男一, 不能赢也就全无希望. 第一局曾因地利优势一度9:3领
先, 可惜没坚持到最后. 男双的时候, 我向裁判抗议对手发球过腰, 影响一下他的发球,
嘻嘻.
第四场对建研, 等到下午四五点, 之前我们轮空一场, 以逸待劳等着建研与化院的恶拼(2
:3)结束. 看到了他们的出场顺序, 与我们的预料一致(他们有小分的压力, 需要尽早结束
). 我们出王,姜,戴邹,姜邹,戴. 男双的时候, 虽然他们出的是男一和男二, 可是都体力透
支, 在我们求稳和主要拉后场的打法下还先胜一局(注: 单打我们均打不赢他们), 后来对
方男一找到了治我的办法, 就是在接发球的时候平推我的反手后场, 我无法打到对方后场
, 只能调网前, 而他然后就在网前等着. 可我们主要就是靠戴发球时得分, 这样一个回合
只能得一分. 苦于当时没有找到对付这一招的办法, 后来才想到对他发球的时候应该直接
站左右场, 发大球, 可惜这个'后来'都是比赛结束后. 第三局打到了13:15, 最后一球是在
我接发球的时候推到了后场边线外, 我居然还怀疑球是否碰到了对方的身体, 现在想想真
是不应该, 那边有我们的队员看着, 碰到会很明显的, 他自己也不会耍赖. 输了, 还没风
度. 失败. 以0:3结束我们系本次比赛(0:2,0:2,1:2), 收拍子回家.
值得高兴的是由去年的全败到今年胜一场, 算是一点进步, 虽然跟分组运气有关; 另外从
去年的无知到今年能正确分析局势并基本能预计结果, 算是一个较大的进步, 虽然也就是
这一年多认识一些人, 主要是戴的功劳; 可喜的是戴的进步非常大, 明年定是我们的绝对
主力.
总体上, 无论是从分组, 场次安排, 场地选择, 人次安排, 都对我们有很大的好处, 占尽
了天时地利; 哎, 看来人才是最重要的, 寄希望于戴的崛起和我们整体实力的提高.
感谢陈老师全天陪伴我们的失败, 并带给我们巧克力和香蕉; 感谢戴老师提供球我们训练
; 感谢啦啦队队长兼队员张旭东同学的支持(呜呜, 我们一定要增强实力, 让同学们对我们
有信心, 才会来给我们加油助威); 还记得去年陈庆荣也去观看了比赛的, 谢谢他. 可惜我
们只带给了他们失望.
星期一, 十二月 19, 2005
星期三, 一月 12, 2005
自我介绍-电脑篇
作 者: zouyc
标 题: 自我介绍-电脑篇
时 间: Wed Jan 12 17:05:36 2005
本机, made in China. 出厂于上个世纪七十年代末. 由于出厂日期早, 所以配置低, 速度慢. 单CPU, 不可并行.
先说内存, 本机未配备ROM格式的硬盘, 只有RAM内存, 所以内存显得非常重要, 也成为性能的一大指标. 但是寻址能力很弱, 不能统计出内存的具体大小, 不过我可以负责任地说, 一定超过1G bits. 由于RAM格式的存储器需要定期刷新以保存数据不丢失, 而本机并没有足够的CPU时间做刷新工作, 所以实际上每时每刻都有数据丢失现象发生, 无论是新近存储的还是以前保留的. 正是由于这个恼人的数据存储方式的落后, 使得本机的工作方式大大地落后.
首先是软件的安装极其缓慢. 本机出厂两年之后才能开始安装操作系统, 很荣幸是中文界面的, 据说这种操作系统门槛比较高, 要是先装了别的系统再兼容中文系统就很困难了. 本机正在兼容english过程中, 也很难呀. 由于Locale的问题, 以后的很多年还要向统一标准(就是普通话啦)逐步靠拢, 直到有一天要和一堆Locale和我都不一样的机器交换数据的时候, 我们才最终使用相同的标准.
软件的安装是一件耗时又痛苦的过程, 主要原因是不能从内存到内存的直接拷贝, 而是要通过摄像头和麦克风输入CPU, 再由中央处理器慢慢慢慢的处理后, 才存入到内存. 有的机器甚至由于摄像头超载, 以致于后来需要增加一块凹透镜才能正常成像到焦平面上. 从出厂到现在, 几乎大部分时间都是在装软件, 存数据. 本机现装有中英文处理程序, 逻辑分析程序, 数学软件若干, 物理应用软件一小套, 并均保持升级中. 存储有中英文字词若干, 诗词几首, 小说几部, 图片若干, 并由于CPU长期无法扫描到, 部分数据正在丢失中.
所幸还有另外一种存储方式--光盘(纸啊), 虽然容量比较小, 每平方厘米也就能存储两三个字节, 不过材料廉价, 大家一般也不屑于可擦除式刻录(铅笔), 而是一次性使用. 这样也极大地方便了数据的传播. 以致于大多数软件都是通过光盘安装.
在外设方面配置倒是不错的. 最大的好处就是具有可移动性. 可移动也许就要被问到电池的容量, 准确地说, 这个没有试过, 因为断电不仅会造成RAM的数据全部丢失, 更是因为本机不具有重启功能, 所以测试电池容量的实验极其危险. 基本数据还是可以提供, 据说不提供任何补给, 可以支撑七天, 如果提供H2O的话, 可以支撑13天. 不过提醒各位用户千万不要测试, 极有可能是不可逆操作, 无法实现undo功能. 正常情况只需每天充电三次, 每次四十分钟左右, 示情况而定. 本机还是希望是太阳能的就好了, 但是纵观全球, 能实现太阳能充电的都没有可移动性, 不能动的东东, 大家就叫他们植物喽, 我不想做植物. 移动性能极大发挥了本机的主观能动性, 但是有时也会导致灾祸, 如刚出厂不久, 由于和外设的兼容性还没有调节好, 在充电时不小心接触了强红外线幅射源, 使得机箱的油漆蹭掉了一块.
音箱由于只有单声道, 不提供立体声效果, 但是能高保真. 显示器采用无穷位真彩色, 但屏幕背景不漂亮, 还不能换.
其他恕不一一细表. 系统仍在升级, 数据仍在丢失...
标 题: 自我介绍-电脑篇
时 间: Wed Jan 12 17:05:36 2005
本机, made in China. 出厂于上个世纪七十年代末. 由于出厂日期早, 所以配置低, 速度慢. 单CPU, 不可并行.
先说内存, 本机未配备ROM格式的硬盘, 只有RAM内存, 所以内存显得非常重要, 也成为性能的一大指标. 但是寻址能力很弱, 不能统计出内存的具体大小, 不过我可以负责任地说, 一定超过1G bits. 由于RAM格式的存储器需要定期刷新以保存数据不丢失, 而本机并没有足够的CPU时间做刷新工作, 所以实际上每时每刻都有数据丢失现象发生, 无论是新近存储的还是以前保留的. 正是由于这个恼人的数据存储方式的落后, 使得本机的工作方式大大地落后.
首先是软件的安装极其缓慢. 本机出厂两年之后才能开始安装操作系统, 很荣幸是中文界面的, 据说这种操作系统门槛比较高, 要是先装了别的系统再兼容中文系统就很困难了. 本机正在兼容english过程中, 也很难呀. 由于Locale的问题, 以后的很多年还要向统一标准(就是普通话啦)逐步靠拢, 直到有一天要和一堆Locale和我都不一样的机器交换数据的时候, 我们才最终使用相同的标准.
软件的安装是一件耗时又痛苦的过程, 主要原因是不能从内存到内存的直接拷贝, 而是要通过摄像头和麦克风输入CPU, 再由中央处理器慢慢慢慢的处理后, 才存入到内存. 有的机器甚至由于摄像头超载, 以致于后来需要增加一块凹透镜才能正常成像到焦平面上. 从出厂到现在, 几乎大部分时间都是在装软件, 存数据. 本机现装有中英文处理程序, 逻辑分析程序, 数学软件若干, 物理应用软件一小套, 并均保持升级中. 存储有中英文字词若干, 诗词几首, 小说几部, 图片若干, 并由于CPU长期无法扫描到, 部分数据正在丢失中.
所幸还有另外一种存储方式--光盘(纸啊), 虽然容量比较小, 每平方厘米也就能存储两三个字节, 不过材料廉价, 大家一般也不屑于可擦除式刻录(铅笔), 而是一次性使用. 这样也极大地方便了数据的传播. 以致于大多数软件都是通过光盘安装.
在外设方面配置倒是不错的. 最大的好处就是具有可移动性. 可移动也许就要被问到电池的容量, 准确地说, 这个没有试过, 因为断电不仅会造成RAM的数据全部丢失, 更是因为本机不具有重启功能, 所以测试电池容量的实验极其危险. 基本数据还是可以提供, 据说不提供任何补给, 可以支撑七天, 如果提供H2O的话, 可以支撑13天. 不过提醒各位用户千万不要测试, 极有可能是不可逆操作, 无法实现undo功能. 正常情况只需每天充电三次, 每次四十分钟左右, 示情况而定. 本机还是希望是太阳能的就好了, 但是纵观全球, 能实现太阳能充电的都没有可移动性, 不能动的东东, 大家就叫他们植物喽, 我不想做植物. 移动性能极大发挥了本机的主观能动性, 但是有时也会导致灾祸, 如刚出厂不久, 由于和外设的兼容性还没有调节好, 在充电时不小心接触了强红外线幅射源, 使得机箱的油漆蹭掉了一块.
音箱由于只有单声道, 不提供立体声效果, 但是能高保真. 显示器采用无穷位真彩色, 但屏幕背景不漂亮, 还不能换.
其他恕不一一细表. 系统仍在升级, 数据仍在丢失...
星期六, 一月 01, 2005
xmgrace 笔记
xmgrace
xmgrace 是一个类似于origin的数据图像化的软件, 现在用的当前版本是Grace5.18. 主要就是将数据转化成图形, 可以保存, 以使以后继续分析, 也可以输出为eps等可视的图像结果. 下面是一个xmgrace的截图:
xmgrace1.png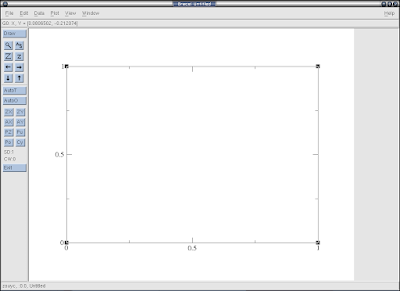
然后点击菜单栏中的data, 出现下面的东东
xmgrace2.png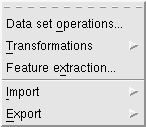
点import中的ascii选择从文件导入数据, 注意文件需要有两列, 一列横坐标, 一列纵坐标, 出现下面的窗口
xmgrace3.png
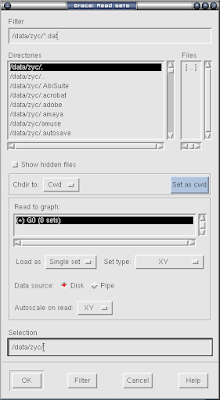
浏览文件夹, 选择需要画图的文件. 可以先选中Drectories的某个文件夹, 有时不能双击成功, 可以点最下面的Filter按钮, 就进入那个文件夹下了. 黑条那里可以点右键, (注意, xmgrace中点右键一般不能放开) 选择kill可以把当前的已有的东西全部干掉, 然后在点右键, 选Creat New新建一个, 这时要注意选中这个新建的东东, 把它点黑, 嘿嘿. 然后点右上方的文件, 选中就画图, 想点几个就点几个. 点ok画图, 点cancel干掉这个弹出来的窗口, 不要被cancel这个词吓着了而不敢点. 好, 现在图就画好了. 这个样子的
xmgrace4.png
图中的四个角可以双击, 来改变图的大小, 也可以把图拉得小一些, 然后上面放着很多个图. 方法是在'plot -> graphic appearance -> edit'中点击 'creat new', 然后在图的边框的角上双击, 拖动以改变大小. 给个例子:
xmgrace5.png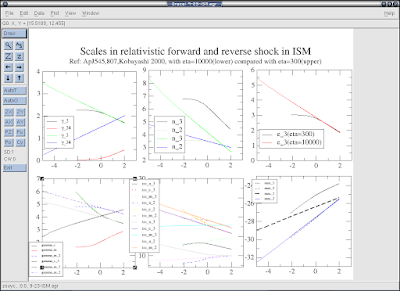
好, 先不管上面一些花哨的东西, 一步一步地来. 对图形操作选项最多的在plot菜单中, 当然, 也可以图中使劲地双击左键, 运气好的话也能点出自己想要的. 还是看plot,
xmgrace6.png
其实基本上就可以在这四个里边一个一个地试了. 还是做一个简单的介绍.
第一个, Plot appearance 是画图的一些大体上的设置, 不多罗嗦.
Graph appearance 主要是给这个图一个标题, 分主标题和次标题, 可以不填. 填的时候有时侯鼠标点到那个地方会无法输入字母, 这时点点其他的东东, 或者关掉重来, 试几下, 就又可以输入了.
xmgrace7.png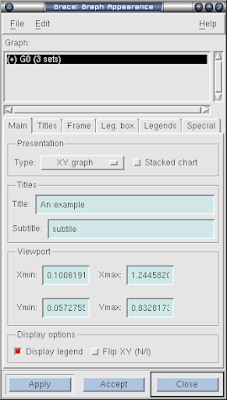
这里边有很多子菜单, 基本上就是为这两个title服务的, 慢慢点吧. 不过Leg.box和Lengends不是, 这个是用来定图中曲线说明的位置的. 就是上上个图中几个小框框的位置.
下面是效果
xmgrace8.png
再看第三个, set apperance.
xmgrace9.png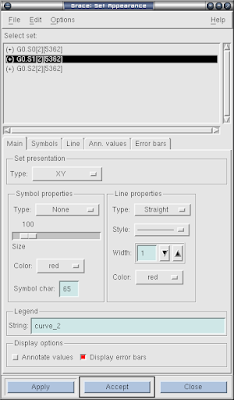
就是用来设置对曲线的说明的了, 就是前面提到过的legend. 修改lengend中的文字来表示各条曲线是什么意思. 其他子选项基本都是为这个Lengend服务的. 注意我们提到前面Plot appearance , 是用它来修改lengend的位置的, 要小心. 通过修改到一个比较宽敞的位置, 得到这样的截图
xmgrace10.png
最后一个, Axis properties.
xmgrace11.png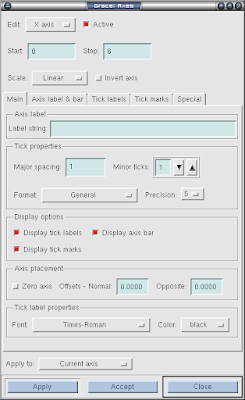
全部是关于坐标轴的, 包括坐标的名称, 是用线性的还是对数坐标, 坐标的范围, 坐标的标记(tick mark)等等. 注意这里的名称, 包括上面的标题名称等只要能写字的地方, 都可以写罗马字母等其他符号的, 选择Font即可.
那个图中还有后面两项: Save parameters和Load parameters, 就是把上面的这些辛辛苦苦设置好的东东保存下来, 这些保存的是不带数据的, 以后画其他数据的时候, 就可以把这些设置拿过来用了.
好, 图画好之后就是把它导出了, 选择File->print setup
xmgrace12.png
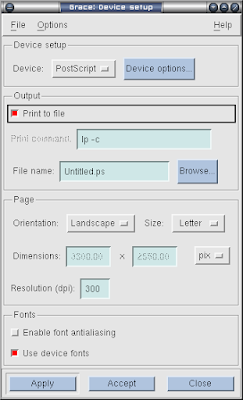
选中Print to file, 然后给File一个名字, 如果不些, 它就默认了, 现在是Untitled.ps, 如果文件保存成foo.agr文件了, 这里就显示为foo.ps, 然后点Accept; 再File->Print就输出成ps文件了.
在菜单栏中有window项
xmgrace13.png
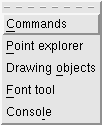
其中的Drawing objects是很有用的, 可以在窗口中随意写上一些东西的
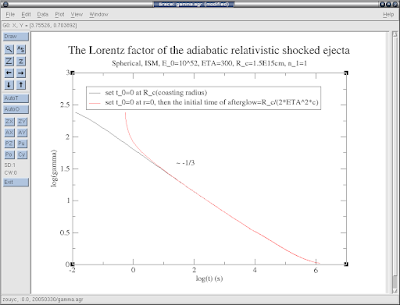
xmgrace14.png
主要是四项: text, line, box, ellipse, 其他都是为这四项服务的, 下面有个截图, 其中-1/3就是这样弄上去的(用text)
xmgrace15.png
最后把这个东西保存下来, File->Save, 以备日后修改或者还没做完而继续做.
另外, 点击窗口右上角的help, 有很详细的介绍.
grace有相当复杂的字符控制格式, 可以在一行中输出各种复杂的字符和格式, 如希腊字符, 上下标等, 详细介绍在/usr/share/grace/doc/UsersGuide.html中的typesetting一节中.
一些其他技巧:
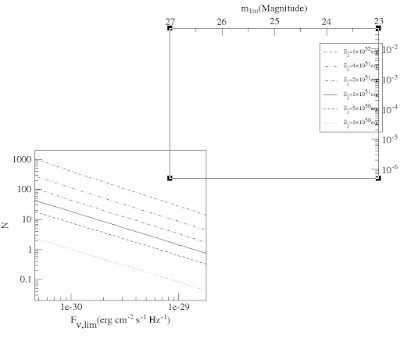
怎样对两个横轴和纵轴作不同标度的刻度?
答案是画两个图, 一个画左纵轴和下横轴的刻度, 一个画右纵轴和上横轴的刻度, 把这两幅图叠起来即可.
下面这是最后结果
Grace-two-axis.png
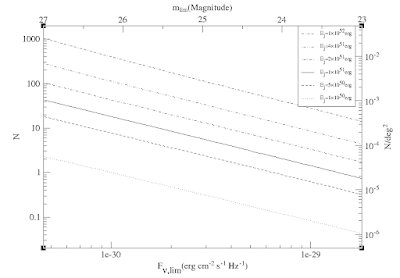
其实拉一拉, 原来是由这两个图凑在一起的!
Grace-two-axis1.png
xmgrace 是一个类似于origin的数据图像化的软件, 现在用的当前版本是Grace5.18. 主要就是将数据转化成图形, 可以保存, 以使以后继续分析, 也可以输出为eps等可视的图像结果. 下面是一个xmgrace的截图:
xmgrace1.png

然后点击菜单栏中的data, 出现下面的东东
xmgrace2.png

点import中的ascii选择从文件导入数据, 注意文件需要有两列, 一列横坐标, 一列纵坐标, 出现下面的窗口
xmgrace3.png

浏览文件夹, 选择需要画图的文件. 可以先选中Drectories的某个文件夹, 有时不能双击成功, 可以点最下面的Filter按钮, 就进入那个文件夹下了. 黑条那里可以点右键, (注意, xmgrace中点右键一般不能放开) 选择kill可以把当前的已有的东西全部干掉, 然后在点右键, 选Creat New新建一个, 这时要注意选中这个新建的东东, 把它点黑, 嘿嘿. 然后点右上方的文件, 选中就画图, 想点几个就点几个. 点ok画图, 点cancel干掉这个弹出来的窗口, 不要被cancel这个词吓着了而不敢点. 好, 现在图就画好了. 这个样子的
xmgrace4.png

图中的四个角可以双击, 来改变图的大小, 也可以把图拉得小一些, 然后上面放着很多个图. 方法是在'plot -> graphic appearance -> edit'中点击 'creat new', 然后在图的边框的角上双击, 拖动以改变大小. 给个例子:
xmgrace5.png

好, 先不管上面一些花哨的东西, 一步一步地来. 对图形操作选项最多的在plot菜单中, 当然, 也可以图中使劲地双击左键, 运气好的话也能点出自己想要的. 还是看plot,
xmgrace6.png

其实基本上就可以在这四个里边一个一个地试了. 还是做一个简单的介绍.
第一个, Plot appearance 是画图的一些大体上的设置, 不多罗嗦.
Graph appearance 主要是给这个图一个标题, 分主标题和次标题, 可以不填. 填的时候有时侯鼠标点到那个地方会无法输入字母, 这时点点其他的东东, 或者关掉重来, 试几下, 就又可以输入了.
xmgrace7.png

这里边有很多子菜单, 基本上就是为这两个title服务的, 慢慢点吧. 不过Leg.box和Lengends不是, 这个是用来定图中曲线说明的位置的. 就是上上个图中几个小框框的位置.
下面是效果
xmgrace8.png

再看第三个, set apperance.
xmgrace9.png

就是用来设置对曲线的说明的了, 就是前面提到过的legend. 修改lengend中的文字来表示各条曲线是什么意思. 其他子选项基本都是为这个Lengend服务的. 注意我们提到前面Plot appearance , 是用它来修改lengend的位置的, 要小心. 通过修改到一个比较宽敞的位置, 得到这样的截图
xmgrace10.png

最后一个, Axis properties.
xmgrace11.png

全部是关于坐标轴的, 包括坐标的名称, 是用线性的还是对数坐标, 坐标的范围, 坐标的标记(tick mark)等等. 注意这里的名称, 包括上面的标题名称等只要能写字的地方, 都可以写罗马字母等其他符号的, 选择Font即可.
那个图中还有后面两项: Save parameters和Load parameters, 就是把上面的这些辛辛苦苦设置好的东东保存下来, 这些保存的是不带数据的, 以后画其他数据的时候, 就可以把这些设置拿过来用了.
好, 图画好之后就是把它导出了, 选择File->print setup
xmgrace12.png

选中Print to file, 然后给File一个名字, 如果不些, 它就默认了, 现在是Untitled.ps, 如果文件保存成foo.agr文件了, 这里就显示为foo.ps, 然后点Accept; 再File->Print就输出成ps文件了.
在菜单栏中有window项
xmgrace13.png

其中的Drawing objects是很有用的, 可以在窗口中随意写上一些东西的
xmgrace14.png

主要是四项: text, line, box, ellipse, 其他都是为这四项服务的, 下面有个截图, 其中-1/3就是这样弄上去的(用text)
xmgrace15.png

最后把这个东西保存下来, File->Save, 以备日后修改或者还没做完而继续做.
另外, 点击窗口右上角的help, 有很详细的介绍.
grace有相当复杂的字符控制格式, 可以在一行中输出各种复杂的字符和格式, 如希腊字符, 上下标等, 详细介绍在/usr/share/grace/doc/UsersGuide.html中的typesetting一节中.
一些其他技巧:
怎样对两个横轴和纵轴作不同标度的刻度?
答案是画两个图, 一个画左纵轴和下横轴的刻度, 一个画右纵轴和上横轴的刻度, 把这两幅图叠起来即可.
下面这是最后结果
Grace-two-axis.png

其实拉一拉, 原来是由这两个图凑在一起的!
Grace-two-axis1.png

simplephpblog 笔记
sphpblog: simple php blog
安装和升级都很简单, 按照文件的提示做就是了. 这里列出由Wang Jia同学所做的修改(感谢他先):
1. 使点击类别的时候显示的是文章的标题而不是全文 -- 在themes/../themes.php文件中多加一个判断条件, else里就是所要的内容;
2. 使得cetegories栏显示一个在最最下面, 一便于按一下键盘的end键就到那儿 -- 修改themes.php, 增加了这样一堆东西:
// New 0.3.8. MY.
$result = menu_display_categories();
if ( $result["content"] != "" ) {
echo( "\n\n" );
echo('
其实大部分也就是从上面拷下来的;
3. 把内容栏弄宽一些 -- 修改themes.php中的这一行:
$theme_vars["content_width"] = 650;
4. 把点击类别显示的文章数加大:
修改文件sb_display.php
增加 $blog_max_my = 100;
然后把其中一部分$blog_config[ 'blog_max_entries' ] 改成$blog_max_my
(不准备用它了)
安装和升级都很简单, 按照文件的提示做就是了. 这里列出由Wang Jia同学所做的修改(感谢他先):
1. 使点击类别的时候显示的是文章的标题而不是全文 -- 在themes/../themes.php文件中多加一个判断条件, else里就是所要的内容;
2. 使得cetegories栏显示一个在最最下面, 一便于按一下键盘的end键就到那儿 -- 修改themes.php, 增加了这样一堆东西:
// New 0.3.8. MY.
$result = menu_display_categories();
if ( $result["content"] != "" ) {
echo( "\n\n" );
echo('
');
echo("
echo( "
\n" );
echo("
");echo("
" . $result[ 'title' ] . "
\n" );echo( "
\n" );
echo( $result[ 'content' ] . "\n" );
echo( "
echo( $result[ 'content' ] . "\n" );
echo( "
\n" );
echo("
其实大部分也就是从上面拷下来的;
3. 把内容栏弄宽一些 -- 修改themes.php中的这一行:
$theme_vars["content_width"] = 650;
4. 把点击类别显示的文章数加大:
修改文件sb_display.php
增加 $blog_max_my = 100;
然后把其中一部分$blog_config[ 'blog_max_entries' ] 改成$blog_max_my
(不准备用它了)
Photran 笔记
Photran
Photran是基于java的一个eclipse插件, 用于fortran程序开发的IDE(Integrated Developement Environment).
基本用法(翻译自photran主页的介绍):
1. shell> eclipse
2. File | New | Standard Make Fortran 77 Project;
3. 输入如"hello"作为project的名称, 点Finish;
4. File | New | File;
5. 输入"Makefile", 点Finish;
6. 在新出现的主编辑窗口中输入如:
all:
f77 -g hello.f
clean:
7. File | New | Source File;
8. 输入如"hello.f", 点Finish;
9. 在新建的主编辑窗口中输入如:
program hello
print *, "Hello World"
stop
end program hello
10. Project | Clean, 然后点击OK;
11. 查看Console窗口(下面), 确认没有错误;
12. 在Project窗口(左边)会出现可执行文件, 由于Makefile的原因, 以a.out为名, 选中它;
13. Run | Run As | Local Fortran Application;
14. 选GDB debugger, 点击OK;
15. Console中会出现结果: "Hello World".
GPG 加密, 签名
GPG(GnuPG)--加密, 签名
一份通俗易懂的简短 说明被拷贝在这里. 另一份稍微详细一些, 并有一点点关于加密解密原理的介绍, 不过是繁体的.
使用GnuPG对文 件进行加密 2004-09-16 转自http://linux.xab.ac.cn/article.php/77
| 使用GnuPG对文件进行加密 |
| 使用GPG非常简单,它是一个基于命令行的工具,主要用于给文件进行加密 1.生成密钥 在使用GPG之前,必须生成一对密钥。 [root@tipy root]$ gpg --gen-key 在这之后,你将被问选择哪 种加密方式 DAS AND EIGamal, DAS ,EIGAMAL。 第一个是默认的,它包括GPG的全部特性。一般我们都选择它。 接下来它会问你想要的keysize,默认的keysize是1024 bits(一般都用它),我们 就选它。当然你还可以选择其它的,像2048.....。取决于你的需要。 下一步是设置密码的时间限制。如果不需要密码期限的话就选 0。而如果需要的话 就选其它的,比如 1y 是指一年,还可以指定是天数,周数,月数。 后一步就是输入你的个人信息了,用户ID 由三个部分组成:真名,注解,和Email 地址。只有一个一个输入就行了。 最后一步是输入密码(passphrase),这个密码是解密的时候用的,必须牢记哦。 重复输入一次就over了。 我们可以输入gpg --list-keys 查看我们的key 的信息 2 使用 GnuPG 一 加密 在生成密钥之后,我们就可以开始使用GPG来加密文件了。创建一个文本文件 test.file,输入一些字符,然后保存。 [root@tipy root]$ gpg -ea -r name test.file 其中name是你在上面用来生成密钥时输入的用户名,用这个用户名加密的文件 只能由这个用户名来解密。回车之后就会生成一个 test.file.asc的文件,这个就是加密之后的文件。-e 选项告诉GPG进行加密, -a 选项告诉GPG加密成ASCII,这样适合邮件发送,而且还可以查看。如果不 是加密成ASCII形式,可以加密成二进制。-r 指定加密的用户。 二 解密 [root@tipy root]$ gpg -d test.file.asc >test.file 敲入回车以后,会要求你输入密码,只有输入上面生成密钥时的那个密码就行了, 总结: gpg的使用很简单,还有很多其它有用的性能,有学习兴趣的可以去看一看 http://www.mandrakesecure.net/en/docs/gpg.php 出自:http://www.chinalinuxpub.com/read.htm?id=1371 |
注意: 由于gpg -ea -r name test.file中-r 的name是自己, 也就只有自己能解开了.
要寻求帮助, 永远不要忘了/usr/share/doc/.
待解决:
如何在其他机器或者用其他帐号的时候解密对自己加密的文件?
postscript 笔记
postscript是一种标记语言, 最初有adobe公司开发并免费发布, 用于打印. 后来成为工业标准. 由于ps文件的应用广泛, 也有模拟打印机(如ghostview)在电脑上显示这些文件的软件面试. 由于是矢量存储, 文件的清晰度不随放大或缩小而有所下降, 所以是一种精确格式. postscript的语言是堆栈式的(先进后出), 这个应该是打印机的微处理器有关, 所以它的语言看起来有点儿倒装的感觉.
ps文件一般都是由其他软件生成, 如metapost, gnuplot, gimp等等, 为什么要学postscript语法?
第一, 虽然一般是由其他软件生成, 但我们也完全可以自己写, 而且自己写的一般比程序生成的简短, 易读, 效率高;
第二, 目前还没有可视化的编辑ps文件的工具, 如果想改动一下图中的某些部分的话怎么办? 借助其他图形编辑工具如display是可以达到所见即所得的效果, 但是display编辑过程中并不是矢量格式, 图片被整大, 质量被弄模糊. 所以最好的办法是懂了ps的语言, 自己动手修改文件.
gs(gostscript)
是用于解释ps命令的, 可以在终端运行, 一句一句解释并显示在图上. 本来PostCript是为打印机准备的啦, gs就是模拟一下打印机, 在屏幕上显示了.
ps实战
1. 一个最简单的ps图:
%!
newpath
100 100 moveto
200 300 lineto
stroke
将上面的文字存起来, 叫个simple.ps吧, 然后用gv啊什么的打开就可以看到一条线了!
解释一下这几个字的意思:
%! 是告诉别的程序说这个文件是ps文件, 要是用file命令就可以看到:"simple.ps: PostScript document text", 如果不要这两个字母也没问题, 在postscript语言中%表示说明;
newpath: 重新定路径, 有点初始化的意思, 把以前的path清空, 第一次不写它也行;
100 100 moveto: 就是移动到以象素为坐标的(100, 100)处, 可以想象成移动打印机的激光头;
200 300 lineto: 划一条线(当然是从刚才移动到的地方啦)到(200, 300)的地方;
stroke: over, 显示吧, 这个不能省.
2. 一个写文字的例子
/Times-Roman findfont
12 scalefont
setfont
newpath
100 200 moveto
(Example) show
showpage
都很直观, findfont: 找到并用这个字体(只要机器里有的字体都可以), scalefont: 字体大小, show: 显示()中的字, showpage: 显示该页, 以后的就在下一页了.
如果想写些希腊字母, 可以这样
/Symbol findfont 600 scalefont setfont
6000 1000 M (n) show
showpage
3. 画一条虚线
newpath
100 100 moveto
200 400 lineto
[3] 0 setdash
stroke
其中[3]中的3是dash的长度, 有时侯由于scale的原因, 要很大如100才看得出来. 后面的0是虚线的样式, 可以自己试, 该选哪一种.
[] 0 setdash 表示实线.
哈哈, 成功hack ps图一张(上面是修改后的, 下面是原来的):

原文件在这里, 改过之后的文件在这里! 呵呵, 实际上就是删掉一些.
2005. 10. 6
现在被改成这个样子了:)

ps文件.
2005.10.16
PostScript参考:
书有: PostScript language reference, 3nd edition, Adobe出品, 权威, 详尽, 有900多页啊;
POSTSCRIPT LANGUAGE TUTORIAL and COOKBOOK, ADOBE SYSTEMS INCORPORATED
网页有:
PostScript Tutorial 一个很简略易懂的介绍, 适合初学;
PostScript Program I(我 自己翻译的哦), II, III 比较技术性, 不过I也是很粗浅的.
appendix:
postscript是一种标记语言, 最初有adobe公司开发并免费发布, 用于打印. 后来成为工业标准. 由于ps文件的应用广泛, 也有模拟打印机(如ghostview)在电脑上显示这些文件的软件面试. 由于是矢量存储, 文件的清晰度不随放大或缩小而有所下降, 所以是一种精确格式. postscript的语言是堆栈式的(先进后出), 这个应该是打印机的微处理器有关, 所以它的语言看起来有点儿倒装的感觉.
ps文件一般都是由其他软件生成, 如metapost, gnuplot, gimp等等, 为什么要学postscript语法?
第一, 虽然一般是由其他软件生成, 但我们也完全可以自己写, 而且自己写的一般比程序生成的简短, 易读, 效率高;
第二, 目前还没有可视化的编辑ps文件的工具, 如果想改动一下图中的某些部分的话怎么办? 借助其他图形编辑工具如display是可以达到所见即所得的效果, 但是display编辑过程中并不是矢量格式, 图片被整大, 质量被弄模糊. 所以最好的办法是懂了ps的语言, 自己动手修改文件.
gs(gostscript)
是用于解释ps命令的, 可以在终端运行, 一句一句解释并显示在图上. 本来PostCript是为打印机准备的啦, gs就是模拟一下打印机, 在屏幕上显示了.
ps实战
1. 一个最简单的ps图:
%!
newpath
100 100 moveto
200 300 lineto
stroke
将上面的文字存起来, 叫个simple.ps吧, 然后用gv啊什么的打开就可以看到一条线了!
解释一下这几个字的意思:
%! 是告诉别的程序说这个文件是ps文件, 要是用file命令就可以看到:"simple.ps: PostScript document text", 如果不要这两个字母也没问题, 在postscript语言中%表示说明;
newpath: 重新定路径, 有点初始化的意思, 把以前的path清空, 第一次不写它也行;
100 100 moveto: 就是移动到以象素为坐标的(100, 100)处, 可以想象成移动打印机的激光头;
200 300 lineto: 划一条线(当然是从刚才移动到的地方啦)到(200, 300)的地方;
stroke: over, 显示吧, 这个不能省.
2. 一个写文字的例子
/Times-Roman findfont
12 scalefont
setfont
newpath
100 200 moveto
(Example) show
showpage
都很直观, findfont: 找到并用这个字体(只要机器里有的字体都可以), scalefont: 字体大小, show: 显示()中的字, showpage: 显示该页, 以后的就在下一页了.
如果想写些希腊字母, 可以这样
/Symbol findfont 600 scalefont setfont
6000 1000 M (n) show
showpage
3. 画一条虚线
newpath
100 100 moveto
200 400 lineto
[3] 0 setdash
stroke
其中[3]中的3是dash的长度, 有时侯由于scale的原因, 要很大如100才看得出来. 后面的0是虚线的样式, 可以自己试, 该选哪一种.
[] 0 setdash 表示实线.
哈哈, 成功hack ps图一张(上面是修改后的, 下面是原来的):
原文件在这里, 改过之后的文件在这里! 呵呵, 实际上就是删掉一些.
2005. 10. 6
现在被改成这个样子了:)
ps文件.
2005.10.16
PostScript参考:
书有: PostScript language reference, 3nd edition, Adobe出品, 权威, 详尽, 有900多页啊;
POSTSCRIPT LANGUAGE TUTORIAL and COOKBOOK, ADOBE SYSTEMS INCORPORATED
网页有:
PostScript Tutorial 一个很简略易懂的介绍, 适合初学;
PostScript Program I(我 自己翻译的哦), II, III 比较技术性, 不过I也是很粗浅的.
appendix:
Latex 笔记
content="text/html; charset=utf-8">
lang="en-US">
1.
最简单的 lang="en-US">latex文件
\documentclass{article}
\begin{document}
blabla
\end{document}
blabla里边随便写一些乱七八糟的东东 lang="en-US">,
就能被编译然后看到了 lang="en-US">~.~
中文支持 lang="en-US">,
用 lang="en-US">CJK包 face="Times">
\documentclass{article}
\usepackage{CJK}
\begin{CJK}{GBK}{song}
\begin{document}
试汉字 lang="en-US">
\end{CJK}
\end{document}
2. 注释 lang="en-US">
'%'用来注释 lang="en-US">%后的语句 face="Times">,
编译时忽略 lang="en-US">
块注释 lang="en-US">:
\iffalse
...
\fi
3. 空格 lang="en-US">
\
,~ 二者都可以表示空一格 lang="en-US">;
\,表示空很小一点距离 lang="en-US">,
\:大一点 lang="en-US">,
\;再大一点 lang="en-US">;
\!往回退一点点 lang="en-US">;
\hspace{1cm/10pt/0.1\texwidth}横向空一定距离 face="Times">,
\vspace{...}纵向空一定距离 lang="en-US">;
\phantom{000}中间随便写些什么 lang="en-US">,
宽的字符就空得多一些 lang="en-US">,
窄的字符就空的少一些 lang="en-US">,
比 lang="en-US">\hspace{}强硬一些 face="Times">,
不过在公式对齐时最好还是用 lang="en-US">&,
用 lang="en-US">\phantom比较难调 face="Times">,
而且不方便修改 lang="en-US">.
4. 插图 lang="en-US">,表格
好象 lang="en-US">\label要放到 face="Times">\begin{figure}...\end{figure}环
境的最后才能在引用时正确显示标号(还
没有试清楚).
见下面 lang="en-US">:
例 lang="en-US">:
\begin{table}
\centering
\caption{The $t^{\alpha}$). The
columns are the same as in Table \ref{tab-emission}.}
\begin{tabular}{c|c|c}
\hline
a1 &
b1 & c1 \hline
a2 & b2 & c2 \hline
...
\label{kaka}
\end{tabular}
\end{table}
注意 lang="en-US">label的位置 face="Times">,
在 lang="en-US">{tabular}内而不是外边 face="Times">,
否则就出乱子了 lang="en-US">.
figure的 lang="en-US">label也是 face="Times">.
实际上是 lang="en-US">\label命令必须紧接着 face="Times">\caption命
令给出.
5.
生成索引
face="Times">\usepackage{makeidx}
\makeindex
\begin{document}
body:
\index{a!b} (可以是 lang="en-US">a,
a!b, a!b!c等 lang="en-US">)
\printindex
\end{document}
见到 lang="en-US">\makeindex后 face="Times">latex
foo.tex会自动生成 lang="en-US">foo.idx,
然后在命令行中还要 lang="en-US">makeindex
foo.idx生成 lang="en-US">.ind文件 face="Times">,
然后才能再 lang="en-US">latex
foo.tex.
6. 参考文献 lang="en-US">,
如何使用 lang="en-US">bibtex
首先要建立一个 lang="en-US">foo.bib文件用于存放文献信息 face="Times">,
内容见 lang="en-US">xampl.bib,
有各种格式的 lang="en-US">,
如
face="Times">@ARTICLE{article-minimal,
author = {L[eslie] A. Aamport},
title = {The Gnats
and Gnus Document Preparation System},
journal =
{\mbox{G-Animal's} Journal},
year = 1986,
}
其中 lang="en-US">article-minimal是要被引用时用
的;
然后主文件 lang="en-US">(foo.tex)中做以下的事 face="Times">:
lang="en-US">\cite{article-minimal}
...
\bibliography{foo}
\bibliographystyle{plain}
(别人有个各
种样式的
比较)
最后编译的时候分四步 face="Times">:
1. latex foo.tex (生成 lang="en-US">.aux文件 face="Times">)
2. bibtex foo.aux 3. latex foo.tex 4. latex foo.tex (重
复);
当然 lang="en-US">,
在执行的时候是可以不写后缀的 lang="en-US">,
如 lang="en-US">5. xdvi
foo即可看效果 lang="en-US">.
bibtex会生成一个 lang="en-US">bbl文件 face="Times">,
以后就可以直接修改这个文件 lang="en-US">,
投稿的时候也只需带上这个文件 lang="en-US">,
或者把这个文件的内容拷到 lang="en-US">tex文件中 face="Times">.
参考 lang="en-US">:
man bibtex, bibtex/, "关于参考文献 face="Times">.pdf",
bibtex.chm 或 lang="en-US">LaTeX2e使用手册 face="Times">(即
出版出来的<Latex2e科
技论文排版指南>)中
关于bibtex的 face="Times">appendix.
lang="en-US">7.
用 lang="en-US">bibtex,
如何实现每章后面加上参考文献
\usepackage{chapterbib}
然后看 lang="en-US">chapterbib.sty文件,里面的说明
非常之详细
8.
在一个圆圈里放一个数字 lang="en-US">:
\textcircled{\scriptsize1} 或者
$\bigcirc$\hspace{-7.5pt}1
如何在文中实现带圈的数字 lang="en-US">
答: lang="en-US">1)使用 face="Times">\textcircled{}命
令,后面的参数可以是一个字符或者汉字(配合 lang="en-US">CJK) face="Times">
,甚至也可以是公式,但是它只会给第一个字符或者汉字加上
>
合适的圆圈,字体 lang="en-US">
放缩命令对它也有效,因此可以利用这点实现两个字符加圈的效果,但是需要仔细的 face="Times">
调整尺寸,参考如下命令:
>
\Large{\textcircled{\small{12}}}、 face="Times">\textcircled
{九 lang="en-US">}。 face="Times">
2)使用 lang="en-US">pifont宏包,那里面有很漂亮的带圈的各种
数字符号(仅限于阿拉伯数字,如果想>
使用加圈的中文“一”至“九”就不行了)。在 lang="en-US">.tex
>
文件中尝试下列命令: lang="en-US">\ding{172}>~ face="Times">\ding{211}。 face="Times">
3)在 lang="en-US">GB和 face="Times">GBK字
库中本来就有10个
加圈数字形式,可以直接在CJK中
使用。如果不超过11的 face="Times">>
话应该够用了呵呵:①②③④⑤⑥⑦⑧⑨⑩,这些汉
>
字可以直接使用数字软键盘输入( lang="en-US">>
以智能 lang="en-US">ABC输入法为例,其实大部分输入法都是一样
的):打开软键盘,选择“数字序号”>
即可看到。
9.
记数器解决方案 lang="en-US">
\begin{enumerate}
\item
\item
\newcounter{temp}
\setcounter{temp}{\value{enumi}}
\end{enumerate}
...
\begin{enumerate}
\setcounter{enumi}{\value{temp}}
\item
dd
\end{enumerate}
10. 用 lang="en-US">Latex做幻灯片 face="Times">
目前欣赏 lang="en-US">beamer.
这
里有一个非常齐全的用
latex做
幻灯片的各种方案的比较.
(原始网址是 lang="en-US">http://webpc.shtu.edu.cn/yctang/CteX_Talk/homepage/compare.htm)
11.
如何输出这个字符 lang="en-US">~
1.
\textasciitilde 或者 lang="en-US">2.
\~{}
12. 插入其他格式的图片如 lang="en-US">jpg格式的 face="Times">
(1).最简单的办法是用 lang="en-US">pdflatex进行编译 face="Times">,
于是只需在原文件中写上该图片的名字 lang="en-US">;
(2).用 lang="en-US">graphicx宏包 face="Times">,
(不知 lang="en-US">1,2是否一起用 face="Times">)
13.
一个加超链接的例子 lang="en-US">
\href{http://www.toolscenter.org/products/texniccenter}{TeXnicCenter}
14.
关于特殊字符 lang="en-US">
有一个叫 lang="en-US">symbols-a4.pdf的文件 face="Times">,
里边记录了几千个特殊符号的表示方法 lang="en-US">,
例如 lang="en-US">
 alt="latex-symbols" align="bottom" border="0"
alt="latex-symbols" align="bottom" border="0"
height="227" width="554">
15.
\sqrt的真正用法 lang="en-US">:
\sqrt[a]{b}, 其中 lang="en-US">a是在根号前的那个数字 face="Times">,
如果是 lang="en-US">3,
就是开三次方 lang="en-US">.
16.
使用 lang="en-US">bibtex前面已有介绍 face="Times">,
如何修改 lang="en-US">bst文件 face="Times">?
还是不清楚 lang="en-US">,
不过成功修改了一个 lang="en-US">:
FUNCTION
{article}
{ output.bibitem
format.authors "author"
output.check
author format.key output
%%%%%
name.or.dash
format.date "year" output.check
date.block
eprint missing$
{
crossref missing$
{
journal
"journal"
output.check
format.vol.num.pages
output
}
{
format.article.crossref output.nonnull
format.pages output
}
if$
format.journal.pages
}
{eprint output}
if$
format.note output
fin.entry
}
这个 lang="en-US">function就是对 face="Times">bib文
件的条目为article的
进行整理的,
原来对于是预印本文献 lang="en-US">,
我的 lang="en-US">bib条目是
@ARTICLE{2006astro.ph..1063Z,
lang="en-US">author = {{Zhang}, B. and {Gil}, J. and {Dyks}, J.},
lang="en-US">title = "{Physical Interpretations of Rotating Radio Transients}",
lang="en-US">journal = {ArXiv Astrophysics e-prints},
lang="en-US">eprint = {arXiv:astro-ph/0601063},
lang="en-US">year = 2006,
lang="en-US">month = jan,
lang="en-US">adsurl = {http://adsabs.harvard.edu/cgi-bin/nph-bib_query?bibcode=2006astro.ph..1063Z&db_key=PRE},
lang="en-US">adsnote = {Provided by the Smithsonian/NASA Astrophysics Data System}
}
其中有eprint项 face="Times">,
但是在所用的 lang="en-US">aa.bst中没有 face="Times">,
结果显示为 lang="en-US">Zhang
..., ArXiv Astrophysics e-prints, ..., 而没有 face="Times">arXiv:astro-ph/0601063,
结果参考文献的这个条目根本不能确定是哪一篇文献 lang="en-US">.
解决办法就是在 lang="en-US">aa.bst中最前面声明 face="Times">journal,
year...的地方加上 lang="en-US">eprint,
然后如上加上红字部分 lang="en-US">,
意思是如果 lang="en-US">eprint项是空的 face="Times">,
那么按照正常的显示期刊 lang="en-US">,
卷号 lang="en-US">, 页码 face="Times">,
如果不空 lang="en-US">,
则不显示这些 lang="en-US">,
而只输出 lang="en-US">eprint中的内容 face="Times">.
相应的参考文献有 lang="en-US">btxhack(设计 face="Times">bst文
件),
btxdoc(针对 lang="en-US">bib文献 face="Times">,
是 lang="en-US">bibtex的用法 face="Times">).
在 lang="en-US">tex的发行中都包含了 face="Times">.
17.
要生成一个自己想要的 lang="en-US">bst样式文件 face="Times">,
最好的办法是用 lang="en-US">custom-bib,
找到这个 lang="en-US">tgz的包 face="Times">,
解压 lang="en-US">, 里边有详细的说明 face="Times">,
照着做就是了 lang="en-US">.
简单说就是 lang="en-US">latex
编译文件 lang="en-US">,
按提示选则 lang="en-US">,
最终生成 lang="en-US">bst文件 face="Times">.
18.
安装 lang="en-US">CJK的 face="Times">GBK字
体(这
会设计到版权问题的:()
首先是 lang="en-US">CJK已经装上了 face="Times">,
下载 lang="en-US"> target="_blank">ftp://ftp.cc.ac.cn/pub/cct/CJK/上
的CJK-GBKfonts并
装上,
就有 lang="en-US">gbkfonts和 face="Times">gbkfont-inst明
令了.
找 lang="en-US">simsun.ttf,
simkai.ttc等这样的文件 lang="en-US">,
运行 lang="en-US">sudo
gbkfont-inst simsum.ttf gbksong 就可以了 face="Times">!
然后可以用第 lang="en-US">1条里提到的 face="Times">CJK文
件测试一下.
19.
在用了 lang="en-US">natbib这个 face="Times">style文
件之后,
可以方便的用 lang="en-US">\citet,
\citep等引用 lang="en-US">,
但是不同的杂志可能要求的格式不一样 lang="en-US">,
如 lang="en-US">ApJ要 face="Times">"Author,
year", 而 lang="en-US">A&A要 face="Times">"Author
year"(注意中间的逗号的有无 lang="en-US">),
这时只需在文件开头加上 lang="en-US">
\citestyle{aa}即可 lang="en-US">,
当然其中是 lang="en-US">aa还是其它的要看需求和 face="Times">natbib所
提供的.
要查看 lang="en-US">natbib提供了什么 face="Times">,
之间看 lang="en-US">natbib.sty文件就是了 face="Times">.
20.
latex2html命令可以将 lang="en-US">tex文件转化成 face="Times">hmtl文
件。
不过一般会把文件转化成很多页面,浏览的时候需要不停地点击。如果想生成的页面只有一页,则可以 face="Times">
latex2html
-split +0 foo.tex
21.
\tableofcontents
的 lang="en-US">options,在用 face="Times">beamer的
时候偶然看到的一些,不知道可不可以在其他地方用,命令的意思很明显,根本不用解释,其中 lang="en-US">hidesubsections就是通过 face="Times">hideothersubsections自
己联想了一下试出来的,因为没找到在哪里有 lang="en-US">options的介绍,用法:
\tableofcontents[current,currentsubsection,hidesubsections,hideothersubsections]
22.
\part
可以把一个整体分成几个部分,不影响整体的结构
lang="en-US">TIPS
lang="en-US">1.
更新包文件 lang="en-US">(.sty)--mktexlsr;
2.
参考文献数据 lang="en-US">:
bibtex在 lang="en-US">adsabs.harvard.edu上有他们
索引的文章bib
entry, 对天文来说足够用了 lang="en-US">(位置是每篇文章摘要的下面有个链接 face="Times">);
3.
Latex新书 lang="en-US">:
LATEX实用教程(英文版 face="Times">·第 face="Times">4版) face="Times">,
出 版社: href="http://211.100.16.156/dangdang.dll?key=%E6%9C%BA%E6%A2%B0%E5%B7%A5%E4%B8%9A%E5%87%BA%E7%89%88%E7%A4%BE&showall=0&mode=13">机
械工业出版社 出版日期: lang="en-US">2005-4-1
最后更新 lang="en-US">:
2006.4.22
maxima 笔记
Maxima
GNU Maxima 是一种用LISP编 写的自由计算机代数系统, 用于公式推导和符号计算。它由麻省理工学院在 美国能源部的支持下于60年代末创造的 Macsyma 演变而来。 从1982年开始, Bill Schelter 教授默默无闻地维护 Maxima 直到2001年他去世。1998年,Schelter获得能源部许可,以GNU GPL许可证发行Maxima。现在的 Maxima 由独立的用户和开发人员维护。
上面是在wikipedia上copy下来的简介.本页导航: tips, 编程, 扩展, 命令, 变量, 问题, 参考资料
我 粗略地估算了一下, 大概有1600多个命令, 估算方法是按个首字母, 然后按tab键自动补齐, 估计每个首字母的命令个数, 然后加起来. ft, 是1806个, 直接按tab键它就会问我是否显示所有1806个可能选项.
tips
1. 在emacs中运行maxima(这个既方便又好看):
M-x imaxima (但是现在运行有问题, 等一会儿, 然后按C-g, C-x b *maxima*, 才行, 而且是字符显示而不是latex公式, 所以还不如用命令行; 另外现在输入输出提示符不是'C1,D1'而是'%i1,%o1', 不知道是否因为升级了, 检查版本号又好象没有升级, 是11.6号, 这个可能对emacs出现不兼容)
前提是装好了emacs的Maxima mode包, 并在.emacs文件中加入:
(autoload 'maxima "maxima" "Maxima interaction" t)
一些快捷键: M-tab: 自动补齐; 鼠标中键可以将前面的输入送到当前, 以便编辑;
2. 常用命令:
退出: quit(); (注意要有括号和分号) 不能用ctrl-c(新版已经可以用Ctrl-c来取消了), 会进入调试模式, 退出用:q
3. 一般用法:
3.1 .max文件的用法
如果foo.max文件(不一定要这个后缀名)是一个一串maxima执行语句, 可在命令行用 "maxima <> foo.out" 将输出结果直接写入foo.out文件中.
3.2 save and load:
比较郁闷的是maxima中没有保存的功能, 保存下来的东西是文本形式的, 再次打开就不认
识. 可以用batch代替, 作法是:先写好一个maxima能执行的文件"foo", 然后在maxima中batch("foo"); 就会批量执行, 如果要修改什么的话, 去修改原来的文件, 再在这边batch.
例:
文件foo:
c : 2$
c^2;
maxima中:batch("路径/foo"); 会输出:
2
4
4. 怎么写下标?
Example: n\\_1即可,就是要两个斜线。 参见14.1"与Latex结合"
5. Maximia直接将单词转化为希腊字母,如输入pi;输出则为希腊字母的“pi”。但是后面跟了东西就不变 了,如 gamma_3。
但是eta和ETA都是小写的,gamma和GAMMA都是大写的,怎么区分大小写呢?
6. 关于保存然后打开:
6.1
(C1) x:'y;
(D1) y
(C2) foo(x):=1+x;
(D2) foo(x) := 1 + x
(C3) save("myworld.lisp",all);
(D3) myworld.lisp
You restore a saved session by loading the corresponding file in the
usual way
(C1) load("myworld.lisp");
(D3) myworld.lisp
(C4) foo(x);
(D4) y + 1
(C5) fundef(foo);
(D5) foo(x) := 1 + x
但是我这样做就不成功, 初步原因是保存后的文件最开始是三个分号";;;", 在lisp里是说明, 但是在maxima里是结束的标志, maxima看到这个后就报错, 因为分号前没有任何动作, 然后就不往下继续了. 不知道怎么解决.
6.2 用writefile("foo"); 和 closefile(); 配对, 可以把这二者之间的内容原封不懂地保存到foo文件中, 用来以后查看. 注意, 只能看.
7. 启动的maxima总是自己开一个页面,使得顶上的tab栏中其它的buffer都看不到了,解决办法:
1. M-x maxima/imaxima 2. quit(); 3. M-x imaxima
8. 加撇号表示不演算
如: diff(x^2,x); 的结果是2x, 'diff(x^2,x) 是 d x^2 / d x
9. 常数的表示法:
前面加%, 如%pi, %e. 好象也就只有这两个常数.
10. 自带例子:/usr/share/maxima/5.9.1/demo/
用法: demo("/usr/share/maxima/5.9.1/demo/demo.dem");
demo和batch功能相同, 区别是demo是每执行一步要敲一下回车, batch一次性执行到结束或错误处.
11. 获取帮助的方式:
(1) help(); (2) describe(); example(); (3) demo(); (4) info maxima 内容与(2)相同 (5) maximabook (6)maillist 几乎就这么多了. info里边有个function and variable index, 如果想详细了解某个命令的的说明, 可以参考, 比较实用.
12. 任意精度
关键词: bfloat, FPPREC, block
例(copy from mailist):
(C1) float(%pi);
(D1) 3.141592653589793
(C2) bfloat(%pi);
(D2) 3.141592653589793B0
(C3) float(%pi*10^5);
(D3) 314159.2653589793
(C4) bfloat(%pi*10^5);
(D4) 3.141592653589793B5
(C5) FPPREC:100;
(D5) 100
(C6) float(%pi);
(D6) 3.141592653589793
(C7) bfloat(%pi);
(D7)
3.14159265358979323846264338327950288419716939937510582097494459230781640#
6286208998628034825342117068B0
(C8) FPPREC:5;
(D8) 5
(C9) float(%pi);
(D9) 3.1416
(C10) bfloat(%pi);
(D10) 3.1416B0
(C11) FPPREC:16;
(D11) 16
(C12) float(%pi);
(D12) 3.141592653589793
(C13) bfloat(%pi);
(D13) 3.141592653589793B0
(C14) FPPREC:40;
(D14) 40
(C15) float(%pi);
(D15) 3.141592653589793
(C16) bfloat(%pi);
(D16) 3.141592653589793238462643383279502884197B0
(C17) block([FPPREC:100],bfloat(%pi));
(D17)
3.1415926535897932384626433832795028841971693993751058209749445923078164#
06286208998628034825342117068B0
(C19) bfloat(%pi);
(D19) 3.141592653589793238462643383279502884197B0
小结: float和bfloat的精度默认都是16, 如果FPPREC>16, 只影响bfloat(float的最大精度为16, 可以小但不能大), 而如果FPPREC<16, 则float和bfloat都会受影响; 但是FPPRINTPREC的值无论多少都只对bfloat有效.
但是用tex来显示比较小的指数的时候并不听话:
(%i2360) FPPREC:6;
(%o2360) 6
(%i2361) tex(float(1/3));
$$0.3333$$
(%o2361) FALSE
(%i2362) tex(float(1/3*10^-24));
$$3.3333333333333335 \times 10^{-25}$$
(%o2362) FALSE
(%i2363) tex(float(1/3*10^-2));
$$0.0033$$
(%o2363) FALSE
13. 关于注释
方法与c语言相同, 是 "/*...*/". 在emacs里只要/* 后面的就都变颜色了, 但是语法上还是要两个对应, 否则maxima会报错.
14. 与latex结合
14.1 如何输入latex中的A_{2,1/2}?
A_\{2\,1\/2\}
注意那个逗号,除号前面都要加斜杠(花我好长时间找帮助啊, 最后还是试出来的)=_=.
例2: A_{*,-1}要表示成A_\{\*\,\-1\}
如果是特殊字符, 在latex中是一斜杠, 在maxima中要用两斜杠, 如
\alpha 要写为 \\alpha
14.2 更方便地输入一个比较复杂的符号
(%i2) load("mactex-utilities")$
(%i3) texput(st,"\\Sigma_t");
(%o3) \Sigma_t
(%i4) tex(st^2);
$$\Sigma_t^2$$
14.3 对于下标只有一个数字的情况
(%i9) tex(k_1);
$$k__1$$
(%o9) FALSE
(%i10) tex(k_\{1\});
$$k_{1}$$
(%o10) FALSE
不知道是不是一个bug.
14.4 tex()是一个将maxima的表达式变成latex表示的工具
一个需要小注意一下的:
system("echo 'The flux density for the case $\\nu < \\nu_c < \\nu_m$
$F_\{\\nu\,j\}$: ' >> jet.tex")$
可以!
system("echo 'The flux density for the case $\\nu < \\nu_c < \\nu_m$ $F_\{\\nu\,j\}$: '
>> jet.tex")$
不行!
想一想, 在命令行中下面的也是不行的, 不准许还没写完, 也没有续行符就直接按enter的. (与tex关系不大)
14.5
EXPTDISPFLAG:FALSE;
使得tex(x^(-2))的输出是$x^{-2}$而不是$1\over x^2$.
15. 几个图形界面
xmaxima, wxmaxima, symaxx
xmaxima: 独立于maxima, 但界面并不比maxima好看, 一样不能顺眼地显示公式, 是用文本凑的.
wxmaxima: 是maxima的X界面, 以maxima为核心, 显示的公式好看点.
symaxx: 也是maxima的X界面, 多年没有更新了, 不过好象也还不错.
其中wxmaxima可能最好, 不过还是没有结合emacs和latex的imaxima好.
16. 怎样是变量以1/2为指数而不是开根号出现?
有一个专门的变量 SQRTDISPFLAG, 设成 false即可, 另外
DISPLAY_FORMAT_INTERNAL : true;
这个变量还有如下功能:
(%i108) a-b;
(%o108) a + (- 1) b
(%i109) a/b;
- 1
(%o109) a b
(%i110) sqrt(a);
1/2
(%o110) a
maxima中的flag是个很有用的东东, 设置flag的值可以用来控制各种各样的设置, 因为有各种flag, 象:number, exponential, expansion, fatoring. flag就是variable了. 主要控制显示的, 关键词: display.
17. emaxima
在latex中写mamixa代码并执行, 然后都显示在latex文件中. 参考maxima book 3.2.4节. 这里还有一个介绍EMaximaIntro.ps.
例子:
\begin{document}
\usepackage{emaxima}
\begin{document}
\beginmaxima
x^2;
\endmaxima
\end{documnent}
注意要在emacs环境中做, 这样才能用M-x emacs-update-all 来执行其中的maxima代码.
maxima book本身就是用emaxima写的, 所以是最好的example. 现在还有一个例子是自己写的orphan.tex.
\beginmaxima 和 \beginmaixmasession 的区别在于前者把编译前\maximaoutput之前的内容也显示出来了, 而后者没有.
18. 物理常数
load(physconst)$ 就可以直接引用物理常数了.
19. forget和kill
assume(x>1); forget(x);
assume(x>y); forget(x>y);
y:3; kill(y);
y(x):**; kill(y);
小注意: 用kill(all); 来把前面的变量都kill掉, 如果想重新做什么东东的话. 一个好的习惯是在用某个量之前先初始化, 要么赋值(当然可以是表达式), 要么kill它. 也可以kill(a,b);这样kill多个变量的.
20. 随时加个圆括号()好象是没有问题的, 就象latex里没事加个大括号{}样.
21. 赋值, 适合于解出方程后赋值
lhs(x=3)::rhs(x=3); 就相当于x:3;了, 但是不能用lhs(x=3):rhs(x=3);
例如:
(%i1) aa:solve(x-3=0);
(%o1) [x = 3]
(%i2) x;
(%o2) x
(%i3) lhs(aa[1])::rhs(aa[1]);
(%o3) 3
(%i4) x;
(%o4) 3
22. 关于大小写
虽然命令不分大小写, 但是变量是分的, 例如
(%i193) I:2;
(%o193) 2
(%i194) i;
(%o194) i
Maxima开发者好象在做关于大小写的事, 也许是做得更符合习惯吧.
23. noun和verb
maxima中分名词形式和动词形式, noun就是原样照抄, verb就是执行. 不用太在意, 只不过是里边的一个说法而已, 便于表达. 如'sin()就是noun, sin(x)就是verb, 而'diff用的比较普遍.
24. 对前文的引用(quote): %,%%,%i*,%o*,%th(i)
%: 表示前一个输出的结果;
%%: 表示前前一个输出的结果;
%th(i): 表示前i个输出的结果, 注意是相对的, 例%th(1)与%相同;
%i*: 第*个输入, 这是系统自带的仅有的一个引用输入结果的;
%o*: 第*个输出, 和%i是两个绝对量;
另外, 自定义一个, 在mail list上问到的, Viktor回答的,
thi(i):=block([tmp],tmp:concat('%i,linenum-i),ev(tmp,nouns));
然后thi(i)就表示前i个输入的结果了, 当然也可以定义为%thi(), 不过以%为前缀的一般是系统自有的, 最好不要强人家生意:)
这个定义的解释(也是他解释的): concat('%i,linenum-i)将%i和(linenum-i)连接起来, 其中linenum是当前的行数, linenum-i就是所指目标的行数, '%i表示%i不执行(即名词形式), 将这个连接起来的量暂时存到tmp中, ev(tmp,nouns), 将tmp动词化(nouns的作用), 就是所想要的那一行. 实际上就是借用了%i*而已.
发挥一下thi(i):=block([tmp],tmp:concat('%i,i),ev(tmp,nouns)); 就是引用标号为i的那一行的输入. 简化一下就是
thi(i):=(tmp:concat('%i,i),ev(tmp,nouns)); 好象block可有可无, [tmp]也不知道有什么用--申明为本地变量, 而不是全局变量的.
25. 画图
最简单的例子:
plot2d(sin(x),[x,-%pi,%pi]);
一个比较完整的例子:
beta_1: 1.0$
c : 3.D10$
R : 1.D18$
theta_p : 0.50$
gamma: 10$
beta: sqrt(1-1.0/gamma^2)$
/*ksi: c*t/R$*/
ksi0: 0.00001$
assume(ksi>0+ksi0, ksi
plot2d(f_nu,[ksi,1.D-6+ksi0,ksi0+2.0*sin(theta_p)^2-1.D-8], [GNUPLOT_PREAMBLE, "set logscale xy 10"], [GNUPLOT_TERM, PS], [gnuplot_out_file, "tail.eps"]);
_____________
其中[GNUPLOT_PREAMBLE, "set logscale xy 10"], 可改写为[GNUPLOT_PREAMBLE, "set logscale x 10; set logscale y 10"], 注意是分号.
26. 浮点数
设置浮点数的精度:FPPREC, 默认值:16;
设置浮点数的显示长度:FPPRINTPREC, 默认值:0, 即浮点数的事迹精度, 仅对任意精度的bfloat有效;
27. 从表达式中抽值
(%i2) FIRST (3*x*y);
(%o2) 3
还有second...tenth, 比如这里就可以把一个单项式的系数抽出来.
28. SQRTDISPFLAG: FALSE $
使得开根号也以指数形式表示.
29: 局域变量
(%i19) b:1;
(%o19) 1
(%i20) block([b],b:2);
(%o20) 2
(%i21) b;
(%o21) 1
可见block([b]是把b当作局部变量的, 注意block(b,...)不可以, ([b],b:2);也不行.
30: RESET ();
将变量重新设定. 可以通过这个命令看有那些环境变量.
31: 一个编程的好习惯
每一行的内容都可以直接在行首和行尾用/*...*/说明掉. 也就是每一行都是独立的, 这样, 有一些括号, 特别是block的回括号, 就要单独成行(当然, 这个会括号不能随便说明掉).
用maxima 编程
方法一: 写好一个文件, 这个文件是一些命令的堆积, 然后用batch命令执行, 例:
print(The first program);
diff(x^2,x);
然后保存为first.max, 其实扩展名是什么无所谓, 在命令行中输入maxima,
(%i1)batch("first.max");
这样即可.
diff(x^2,x);
然后保存为first.max, 其实扩展名是什么无所谓, 在命令行中输入maxima,
(%i1)batch("first.max");
这样即可.
方法二: 用个括号括起来, 里边的命令之间用逗号隔开, 然后batch它. 好象前面加不加block无所谓.
需要用到的命令: block, ev, map
map: 定义一个过程, 并作用到右面的表达式上,
例:
(%i3) MAP(F,x-y);
(%o3) F(x)-F(y)
(%i4) MAP("=",[A,B],[-0.5,3]);
(%o4) [A = - 0.5, B = 3]
maxima 包
(在/usr/share/maxima/5.9.1/share中找)
用法: load("***.mac"); 也许要加上绝对路径名.
说明: 一般会有一个跟mac文件同名的usg文件, 是用法的说明, 有例子, 也有可能包文件是个lisp文件.
physics
dimension.mac 用来做量纲分析的, 还有一个pdf的说明文件;
physconst.mac 存了很多物理常数在里边;
units.mac 用来做单位转换的;
dimen.mac I don't know.
命 令的用法:
block
block([x,y],arg1,arg2...);
用来将一堆命令堆在一起, 顺序执行, 中间用逗号隔开, 返回最后一个值, 其中方括号的内容表示是本地变量。
和(。。。)的区别就在于block中[x]可以被认出是本地量, 如果不加block这几个字, 也能顺序执行。
多数是用block来写一个子程序或函数, 如
f(x):block([x],x+3);
ev
在ev环境中一步一步地往下做, 输出的是最后的结果, 例
(%i22) ev(x:1/3,float);
(%o22) 0.33333333333333
(%o22) 0.33333333333333
radcan
化简得比较彻底一点. 基本上就是把小数化成分数, 把指数, 对数中的东西化简.
小心:
(%i832) RADCAN(1.E-38);
RAT replaced 0.0 by 0//1 = 0.0
(%o832) 0
会把比较小的量变成0.
变 量的含义:
numer
将含有特殊数字的字符转换成数字, 如果numer为false(默认), 就不转换了.
(%i113) NUMER;
(%o113) FALSE
(%i114) %pi;
(%o114) %PI
(%i115) NUMER:true;
(%o115) TRUE
(%i116) %pi;
(%o116) 3.141592653589793
(%o113) FALSE
(%i114) %pi;
(%o114) %PI
(%i115) NUMER:true;
(%o115) TRUE
(%i116) %pi;
(%o116) 3.141592653589793
问 题:
& nbsp;lisp的文件怎么加载? 肯定不能batch, 因为lisp的说明是用; 表示的, 而;在maxima里是表示语句结束, 我试过, 失败了.
貌似是用load("***.lisp");
解出方程后, 变量怎么在其他地方用? 如结果是[x=4], 但用x的时候, 它还是它自己:( --已解决, 用"::".
在maxima环境中tex然后tab, 看到了tex, texput, texinit, texend, 但是关于后面三个的说明在任何地方都没有找到, 到哪儿去找呢? 这是一个更一般的问题, 就是在info里还找不到的东东, 到哪儿去找?
貌似是用load("***.lisp");
解出方程后, 变量怎么在其他地方用? 如结果是[x=4], 但用x的时候, 它还是它自己:( --已解决, 用"::".
在maxima环境中tex然后tab, 看到了tex, texput, texinit, texend, 但是关于后面三个的说明在任何地方都没有找到, 到哪儿去找呢? 这是一个更一般的问题, 就是在info里还找不到的东东, 到哪儿去找?
参考资料:
作 为参考, maxima info是不可少的, 特点是全, 在emacs里边看也很方便(C-h i); 而maximabook是很实用的, 特点是实用*.*, 一直在更新; mecref.pdf后面的索引比较有查阅价值, 既全面, 全文安排的又有逻辑解构; 下面还有不少其他的参考资料, 作为补充.
这里有一份参考DOE-Maxima Reference Manual, 一个叫Mike的人针对maxima5.9写的参考手册, 是比较全面而又有逻辑体系的.
而一个叫refman16.pdf的文件(本地改名为Macsyma-refman16-1996.pdf, 下载自Richard Fateman 的主页:
http://www.cs.berkeley.edu/~fateman/macsyma/docs), 是Macsyma的官方文档, 内容很丰富, 包括了programming, 目前其他参考文献都没有的.
这里有一份参考DOE-Maxima Reference Manual, 一个叫Mike的人针对maxima5.9写的参考手册, 是比较全面而又有逻辑体系的.
而一个叫refman16.pdf的文件(本地改名为Macsyma-refman16-1996.pdf, 下载自Richard Fateman 的主页:
http://www.cs.berkeley.edu/~fateman/macsyma/docs), 是Macsyma的官方文档, 内容很丰富, 包括了programming, 目前其他参考文献都没有的.
这 里是一份macsyma的介绍, file:///usr/share/maxima/5.9.1/doc/html/intromax.html 叫introduction to MACSYMA, 是2000年的.
而这个才是maxima的介绍, file:///usr/share/maxima/5.9.1/doc/html/maxima_toc.html, 比上面intromax.html要详细很多, 也很新, 2004年10月更新的, 但好象就是maxima info的html版.
Minimal Maxima, 目前的维护者Robert Dodier写的20页的简短而又全面的介绍.
这里是一个" Micro introduction": http://www.math.harvard.edu/computing/maxima/index.html. 一页, 所以弄到本地了, 有一些例子.
有一个叫MaximavsMupad的pdf文档, 介绍Maxima和Mupad的异同, 不过里边举了很多例子, 可以用来学习Maxima的.
TeXmacs与maxima结合,显示的效果就要好不少, 这里(本地)有一份别人的介绍, 原网址是: http://www.inp.nsk.su/~grozin/max-tut/
maxima的mailing list: http://dir.gmane.org/gmane.comp.mathematics.maxima.general, 可以搜索的. 注意, http://gmane.org/,搜集了各种free software的mailing list.
一些个人写的介绍也值得看的, 如王垠的: http://learn.tsinghua.edu.cn/homepage/2001315450/maxima.html, 好象现在还只有他的, 呵呵.
这上面有一些用maxima写成的程序, http://www.mines.edu/fs_home/whereman/software.html, 不过主要是mathematica的程序; 还有 http://www.risc.uni-linz.ac.at/research/combinat/risc/software/Zeilberger/, 是解关于超几何函数的, 要发e-mail申请密码;
这里有一些maxima的功能扩展, 三个画图的, 一个用龙格库塔法数值解微分方程组的, 是葡萄牙人写的 http://fisica.fe.up.pt/maxima/index.html;
别人的笔记.
http://www.vttoth.com/maxima.html maxima一个开发者的网站, 他关心的主要是和相对论相关的矩阵方面.
而这个才是maxima的介绍, file:///usr/share/maxima/5.9.1/doc/html/maxima_toc.html, 比上面intromax.html要详细很多, 也很新, 2004年10月更新的, 但好象就是maxima info的html版.
Minimal Maxima, 目前的维护者Robert Dodier写的20页的简短而又全面的介绍.
这里是一个" Micro introduction": http://www.math.harvard.edu/computing/maxima/index.html. 一页, 所以弄到本地了, 有一些例子.
有一个叫MaximavsMupad的pdf文档, 介绍Maxima和Mupad的异同, 不过里边举了很多例子, 可以用来学习Maxima的.
TeXmacs与maxima结合,显示的效果就要好不少, 这里(本地)有一份别人的介绍, 原网址是: http://www.inp.nsk.su/~grozin/max-tut/
maxima的mailing list: http://dir.gmane.org/gmane.comp.mathematics.maxima.general, 可以搜索的. 注意, http://gmane.org/,搜集了各种free software的mailing list.
一些个人写的介绍也值得看的, 如王垠的: http://learn.tsinghua.edu.cn/homepage/2001315450/maxima.html, 好象现在还只有他的, 呵呵.
这上面有一些用maxima写成的程序, http://www.mines.edu/fs_home/whereman/software.html, 不过主要是mathematica的程序; 还有 http://www.risc.uni-linz.ac.at/research/combinat/risc/software/Zeilberger/, 是解关于超几何函数的, 要发e-mail申请密码;
这里有一些maxima的功能扩展, 三个画图的, 一个用龙格库塔法数值解微分方程组的, 是葡萄牙人写的 http://fisica.fe.up.pt/maxima/index.html;
别人的笔记.
http://www.vttoth.com/maxima.html maxima一个开发者的网站, 他关心的主要是和相对论相关的矩阵方面.
fortran 笔记
实际上是从test.f中直接拷贝过来的:)
!该文档是用来试验各种功能的。可编译!
include 'gammln.for'
program test1
real*8 gammln,x
x=.8
!怎样判断读一个文件到尾了呢?
! read(123,*,end=124)x即可,到了尾端自动跳到标号为124的语句继续执行.
!如果不用open()语句,将自动生成一个文件放东西
write(33,*)'fort.33'
!怎样在循环中中止一个循环,且不用goto语句
!goto语句用来实现跳出循环的功能, 最好不要在让它表示其它跳转, 否则会晕头转向的.
do i=1,10
if(i>5)then
exit !goto 11 !"exit" is not in the f77 standard
endif
enddo
11 print*,'i',i
!怎样做到注释一块的功能,改成“.false.”即可
!其中有输出单引号的写法
if(.true.) then
print*,'''if(.false.) then'' is the same as /*... */ in c, ',
& 'for notation'
endif
!验证是否支持符号的大于、等于号
if ( x < 1.)then
print *,'good! it can recognize <, not only .lt.'
endif
!调用其它fortran程序文件,见开头的include语句
print*,'include ok! 汉字 ok!^.^'
print*,'gamma:',x,' =',exp(gammln(x))
!比较各精度在运算时的转换,6代表屏幕输出,同"*"(同*同d ^^)
write(6,61),1+1.11111111111d0,1.+1.1111111111111D0,2.1111111111D0
print*,'log(e)=',log(2.7)
!求最大值返回双精度要用dmax1()
print*,(dmax1(5.12345678987654321D0,4.D0)),
& max(5.12345678987654321,4.)
!看看是不是把-当成减号了--不是
print*,1.1d-15
61 format(D30.15)
end
!被一个东东害苦了, 写在下面, 以示反省:
! (nu_m/nu_c)**-0.5D0*(nu_a/nu_m)**(-p_hat/2.D0) 错的
! (nu_m/nu_c)**(-0.5D0)*(nu_a/nu_m)**(-p_hat/2.D0) 对的
!可见括号是多么的重要, 以后有事没事就打个括号, 倍儿有面子&.&
!
!小心:
!print*, 4/5 --> 0
!print*, 4/5. --> 0.800000012
!print*, 4./5. --> 0.800000012
!print*, 4.D0/5 --> 0.8
ifort -r8 foo.f -o foo 这样可以将foo.f中单精度的都转换成双精度计算。比如1e56直接编译不了,如果加上r8就可以编译了。而不用改成1d56.
分类内容
库(lib, library): PDA: many useful usage.
输入输出:
print*,'Please select the style of the data you scrached. ',
& '(1. x-y(default), 2. logx-logy, 3. logx-y, 4. x-logy) ',
& 'You can just press ENTER to accept the default choice:'
read'(I3)',i_type !要实现print句中的功能的关键语句
if(((i_type-2)*(i_type-3)*(i_type-4)).ne.0)i_type=1
print*,'i_type: ', i_type !test
如果是"read*,i_type", 则运行的时候程序会一直等着, 直到输入了一个值之后才会往下执行, 而如果加了格式控制之后, 就可以直接按enter, 程序继续往下执行. 而i_type被赋值为1.
赋值:
integer i/0/
integer i
i=0
common语句:;
一个common列表中最好只有一种数据类型, 特别是字符型不能和别的类型混在一个公用数据块中.
一个变量不能出现在两个不同的公用块中.
一些应用:
用龙格-库塔 (Rounge-Kutta)法解常微分方程, 求解非线性方程的解, 求积分 (Romberg Integration)
!参考:Numerical Recipes中的example: xodeinit.for
!用Numerical Recipies上的程序, 采用自适应的变步长方法
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
include "odeint.for"
include "rkck.for"
include "rkqs.for"
program test_Runge_Kutta
implicit none
integer i,kmax,kount,nbad,nok,nvar,NMAX,KMAXX
parameter (nvar=1,KMAXX=200,NMAX=50)
real dxsav,eps,h1,hmin,x,x1,x2,
& y,ystart(nvar)
COMMON /path/ kmax,kount,dxsav,x(KMAXX),y(NMAX,KMAXX)
! common中的数组还有声明的作用, 所以不能再在前面的声明中声明是数组, 否则就重复了, 会报错.
! (NMAX好像是允许Rounge-Kutta法所求方程组的个数, NMAX=50很高了, 注意这些都只是最大的, 实际比这些要小;)
! NMAX: 微分方程组的维数.
! KMAXX 存储中间量的最大数目, 注意这个值还要和子程序中的相一致;
! nvar 实际Rounge-Kutta法中微分方程组的个数.
! 输出量:
! kount 实际存储的中间量的个数, (并不是实际中间计算的步数)
! nbad 试的过程中失败的次数;
! nok 试的过程中失败的次数;
! x() 自变量
! y(i,KMAXX) 结果
external test_eq,rkqs
open(60,file='testEQ.dat')
x1 = 0. !自变量的最小值
x2 = 10. !自变量的最大值
eps = 1.e-10 !最大误差, 用于决定自适应步长
h1 = 1.e-5 !Intial estimated step.
hmin = 1.e-10 !The minimum step. should be in accord with eps.
x(1) = 0. !The initial value.
ystart(1) = 1. !The initial value.
kmax = KMAXX !the max stored number.
dxsav=(x2-x1)/20.0
! The step of stored x, if dxsav .gt. the step with eps,
! otherwise, the step is greaterthan dxsav, regarding the value of eps.
call odeint(ystart,nvar,x1,x2,eps,h1,hmin,nok,nbad,test_eq,rkqs)
write(*,'(/1x,a,t30,i4)') 'Successful steps:',nok
write(*,'(1x,a,t30,i3)') 'Bad steps:',nbad
write(*,'(1x,a,t30,i3)') 'Stored intermediate values:',kount
do 20 i=1,kount
write(60,*)x(i),y(1,i)
20 enddo
close(60)
end
subroutine test_eq(x,y,dydx)
real x(*),y(*),dydx(*)
dydx(1) = y(1) !解就是y=e^x
end subroutine test_eq
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
求解非线性方程的解
!方法:对多项式, 人为取一个大于0一个小于0的两个x1,x2,找中间等于0的x
!参考:Numerical Recipes中的example: xzbrent.for
include 'zbrent.for'
external eq_gamma_3
gamma_3 = zbrent(eq_gamma_3,1.D0,gamma_4,1.D-8)
! eq_gamma_3是一个外部函数作哑元, 第二,三个哑元分别是x1,x2,x在[x1,x2]中, 注意x1和x2的选取要是的中间只有一个根, 否则会漏根; 最后一项是error.
FUNCTION eq_gamma_3(gamma_3)
! see NOTICE: eq_gamma_3
implicit none
real*8 eq_gamma_3
real*8 gamma_3,gamma_4,gamma_34,f
common /C_eq_gamma_3/ gamma_4,f
gamma_34 = gamma_3*gamma_4
& -dsqrt((gamma_3*gamma_3-1.D0)*(gamma_4*gamma_4-1.D0))
eq_gamma_3 = (gamma_34-1.D0)*(4.D0*gamma_34+3.D0)*f
& -(gamma_3-1.D0)*(4.D0*gamma_3+3.D0)
END FUNCTION eq_gamma_3
求积分
1. Romberg Integration
!参考: Numerical Recipes中的example: xqrobm.for
include 'qromb.for'
external fun_D_l
call qromb(fun_D_l,0.D0,z,D)
! fun_D_l是被积函数, 0.D0和z是积分的上下限, D是积分结果
! 误差可以到qromb.for中修改EPS
!
FUNCTION fun_D_l(z)
implicit none
real*8 fun_D_l,omega_l,omega_m,z
! the integral part of the luminosity distance (only for plane universe)
omega_l = 0.7D0
omega_m = 0.3D0
fun_D_l = 1.D0/dsqrt((1.D0+z)*(1.D0+z)*(1.D0+z*omega_m)
& - z*(2.D0+z)*omega_l)
end FUNCTION fun_D_l
但是qromb有局限, 如对跨度太大的积不出来, 例:
fun(x)=1/x**2
call qromb(fun,1.D0,1.D9,result)
结果是:
PAUSE too many steps in qromb statement executed
如果将qromb中的JMAX从20改到30, 在耗时约1分钟之后的结果为23.3017521, 而准确结果是20.73.
2. 用龙格-库塔(Rounge-Kutta)法求积分
方法与求微分方程相同: dy/dx=f(x), 只不过这里是f(x), 即x的函数, 所要的结果是y(1,KMAXX)
注意: f(x)这个函数要连续, 否则计算不出来, 会出现步长下溢.
! to do a integration, output is y(1,KMAXX)
! dydx(1) is the function should be integrated.
include "odeint.for"
include "rkck.for"
include "rkqs.for"
PROGRAM test1
C driver for routine odeint
INTEGER KMAXX,NMAX,NVAR
PARAMETER (KMAXX=200,NMAX=50,NVAR=1)
INTEGER i,kmax,kount,nbad,nok,nrhs
REAL dxsav,eps,h1,hmin,x1,x2,x,y,ystart(NVAR)
COMMON /path/ kmax,kount,dxsav,x(KMAXX),y(NMAX,KMAXX)
COMMON nrhs
EXTERNAL derivs,rkqs
nrhs=0
x1=1.0
x2=10.0
ystart(1)=0.0
eps=1.0e-4
h1=.1
hmin=0.0
kmax=100
dxsav=(x2-x1)/20.0
call odeint(ystart,NVAR,x1,x2,eps,h1,hmin,nok,nbad,derivs,rkqs)
write(*,'(/1x,a,t30,i3)') 'Successful steps:',nok
write(*,'(1x,a,t30,i3)') 'Bad steps:',nbad
write(*,'(1x,a,t30,i3)') 'Function evaluations:',nrhs
write(*,'(1x,a,t30,i3)') 'Stored intermediate values:',kount
write(*,'(/1x,t9,a,t20,a,t33,a)') 'X','Integral'
do 11 i=1,kount
write(*,'(1x,f10.4,2x,2f14.6)') x(i),y(1,i)
11 continue
END
SUBROUTINE derivs(x,y,dydx)
INTEGER nrhs
REAL x,y(*),dydx(*)
real c,h,k,T,nu
COMMON nrhs
c = 2.99792458D10
h = 6.626176D-27
k = 1.380662D-16
T = 1.D4
nrhs=nrhs+1
nu = x
dydx(1) = nu
! dydx(1)= 2.D0*h*nu**3.D0/c/c/(exp(h*nu/k/T)-1.D0)
return
END
C (C) Copr. 1986-92 Numerical Recipes Software ,4-#.
双精度程序
function test_integral(nu)
! test the integration
implicit none
INTEGER KMAXX,NMAX,NVAR
PARAMETER (KMAXX=200,NMAX=50,NVAR=1)
INTEGER i,kmax,kount,nbad,nok,nrhs
REAL*8 dxsav,eps,h1,hmin,x1,x2,x,y,ystart(NVAR),test_integral,nu
COMMON /path/ kmax,kount,dxsav,x(KMAXX),y(NMAX,KMAXX)
COMMON nrhs
EXTERNAL rkqs,ftest
nrhs=0
x1=1.D-6
x2=1.D1
ystart(1)=0.D0
eps=1.0D-4
h1=.1D0
hmin=0.D0
kmax=100
dxsav=(x2-x1)/20.D0
call odeint(ystart,NVAR,x1,x2,eps,h1,hmin,nok,nbad,ftest,rkqs)
write(*,'(/1x,a,t30,i4)') 'Successful steps:',nok
write(*,'(1x,a,t30,i4)') 'Bad steps:',nbad
write(*,'(1x,a,t30,i4)') 'Function evaluations:',nrhs
write(*,'(1x,a,t30,i4)') 'Stored intermediate values:',kount
write(*,'(/1x,t9,a,t20,a,t33,a)') 'X','Integral'
do 11 i=1,kount
write(*,'(1x,D10.4,2x,2D14.6)') x(i),y(1,i)
11 continue
test_integral = y(1,kount)
END function test_integral
subroutine ftest(x,y,dydx)
! test function of integrated for the 'test_integral'
implicit none
integer nrhs
real*8 x,y(*),dydx(*)
common nrhs
nrhs = nrhs+1
dydx(1) = 1.D0
end subroutine
对dydx(1)=1/x**2的测试结果:
eps=1.D-4----- 227320662.
eps=1.D-8----- 1002082.05
eps=1.D-10----- 1000003.2
eps=1.D-14----- 999999.0000240024
eps=1.D-20----- PAUSE too many steps in odeint statement executed
结论: eps不能太大, 太大对积分绝对值也很大的情况, 误差太...大; 也不能太小, 太小会导致不能往下算了. 虽然用起来比Romberg方法麻烦, 但是计算的时候准确度和速度都要好一些.
How to print colored output?
怎样做一个待定长度的数组? 答: 在子过程中 如 real A(*)
怎样决定一个文件的长度? 答: end=
emacs 笔记
C-h,i 到info页面获得帮助, q假退出, 回到原编辑buffer
flyspell: 拼写检查
M-q: 自动断行
键表示:
C: Ctrl, M: Esc 或 Alt, M-x: M+x 或 右手win和Ctrl之间的保存键(可能会随版本有变动).
基本快捷键:
C-x:重复上一次命令;
C-x 左右方向键:切换buffer;
C-k: 删除从光标到行尾的内容;
C-u 0 C-k (或者C-u C-0 C-k): 删除从光标到行首的内容;
C-x 2: 开成两个窗口;
打开和保存:
C-x,C-f 打开; C-x,C-r 以只读方式打开; C-x C-s 保存; C-x C-w 另存为...;
自动对齐: tab
全部自动对齐, 就象每行用了tab键一样的效果: C-M-q
光标移动:
'M-<'开始,'M->'结尾of buffer; 'C-f'forward一字符, 'C-b'backward一字符, 比方向键顺手一点点
C-左右方向键, 以单词为单位移动光标, 比单独用方向键快一点
'C-x r R'设标记R, 'C-x r j R'回到标记R处(也可'C-x j R', 少一个r), 可设多个标记
latex模式:
'C-c,(' 设置label, 'C-c,)'引用label; 'C-c,['建立citation(即引用参考文献), 'C-c,]'(没有反应)
C-c, C-o,自动输入\begin{***}\end{***}
C-c C-f:自动编译tex文件(不好用, 还不如shell下的命令)
fortran模式:
在emacs的info手册中有专门一节讲fortran的, 也有与其他一些程序语言结合的章节, 里边有详细的介绍.
f77的续行: C-M-j, C-c C-d: 逆过程
怎样用粘贴从其他窗口拷贝的内容?
有时候从其他窗口拷贝的内容emacs并不认识, 粘贴不了. 这是因为内容是由几个缓冲区存放的, emacs有时找的不是主缓存, 所以粘贴不了或者粘贴的不是想要的. 有两个解决办法:
1. 在拷贝(或者选中有时也可看成拷贝, 但是在比如firefox中选中和拷贝的是放在两个地方的, 用Ctrl-V和鼠标中间输出的不一样, 这是好事)之后, 来到emacs窗口,
M-x clipboard-kill-region
M-x clipboad-yank
2. 用autocutsel 自动纠正emacs这种非X11的错误,
安装并 .xinitrc 中添加一行:
autocutsel &
要把它放在运行窗口管理器之前,否则它不会被运行!
3. 在X窗口中复制啊粘贴啊, 瞎折腾折腾, 有时侯emacs又可以象其他X窗口一样, 可以粘贴别处拷贝的内容了.
待解决:
想要帮定shift+方向键作为选定用, 这个组合键反正还没有用.
从emacs中往别处拷贝的汉字都是乱码, 怎么办? (暂时用kwrite打开拷贝)
怎样设置, 把win键拿来当M-用?
怎样设置使得自动加载flyspell-mode?
(等我载mozilla composer中编辑修改完准备退出的时候, 总有按C-x,C-s的冲动&.& )
在linuxsir上看到的, 先放这儿, 以后再整理:
选取好程序中的文本块后(可以用C-x h选取整个程序文本),按Esc C-\就会按默认的缩进样式排版该文本块。
可以打印一张refcard,一般常用的DD都搞定了!
这里是我常用的一些:
;; -----------------------------------------------------------------------------------------
;; Some useful commands:
;;
;; C-h w command - to check which key bind to the command
;; C-h k key - to check which command the key bind to
;; C-j - run the lisp command(put the cursor at end)
;;
;; C-c C-t - change mode to hungry-state and auto-state
;; C-c C-a - change mode to auto-state
;; C-c C-d - change mode to hungry-state
;; C-c C-e - expand macro
;; C-c C-\ - add '\' at then end of the line
;; C-u C-s - regular expression search
;; C-x 5 2 - open new frame
;; C-x 5 0 - close new frame
;;
;; M-; - insert a comment
;; M-\ - fixup whitespace
;; M-/ - auto complete the word
;; M-l - downcase-word
;;
;; Mark the region, then
;;
;; C-x r k - kill rectangle
;; C-x r t - insert word in columns
我常用的快捷键:
C-x C-f :打开/新建文件
C-x S :保存所有缓冲区文件
C-x C-v:在当前缓冲区打开文件
C-x k :关闭当前缓冲区
C-x i : 在当前光标位置插入文件
M-x replace-string: 一次性替换字符串
M-x % : 循环替换。
C-s
C-r :查询
C-@ :设置标记,然后选取
C-w :相当于剪切。
M-w :相当于复制
C-y :粘贴
M-y : 循环粘贴。
C-o:开新行
C-f, C-b, C-p, C-n, M-f, M-b, C-v , M-v , C-l, M->, M-<移动。
C - !, 一次性执行shell, M-x shell, 启动shell外壳。
M-x compile:编译程序。
C-x m进入发邮件界面
C-c C-c 发送后离开
Esc x c++-mode,c-mode,python-mode....开始语言模式
C-x C-b列出缓冲区东东
呵呵,上面是我最常用的,
最初由 fog_proxy 发表
问一个问题,我emacs现在在Xwindow下用得很好,唯一的问题是显示的中文字体过大,不知道该如何把字体调小呢?以前也发贴请教过,不过仍然是没 有解决。
Emacs只能使用固定宽度的字体。
用xfontsel命令查看一下可用的字体列表。
然后在~/.Xdefaults或~/.Xresources里修改这一句如:
emacs.Font: *fixed-bold-r-*-14-*-*
flyspell: 拼写检查
M-q: 自动断行
键表示:
C: Ctrl, M: Esc 或 Alt, M-x: M+x 或 右手win和Ctrl之间的保存键(可能会随版本有变动).
基本快捷键:
C-x
C-x 左右方向键:切换buffer;
C-k: 删除从光标到行尾的内容;
C-u 0 C-k (或者C-u C-0 C-k): 删除从光标到行首的内容;
C-x 2: 开成两个窗口;
打开和保存:
C-x,C-f 打开; C-x,C-r 以只读方式打开; C-x C-s 保存; C-x C-w 另存为...;
自动对齐: tab
全部自动对齐, 就象每行用了tab键一样的效果: C-M-q
光标移动:
'M-<'开始,'M->'结尾of buffer; 'C-f'forward一字符, 'C-b'backward一字符, 比方向键顺手一点点
C-左右方向键, 以单词为单位移动光标, 比单独用方向键快一点
'C-x r
latex模式:
'C-c,(' 设置label, 'C-c,)'引用label; 'C-c,['建立citation(即引用参考文献), 'C-c,]'(没有反应)
C-c, C-o,自动输入\begin{***}\end{***}
C-c C-f:自动编译tex文件(不好用, 还不如shell下的命令)
fortran模式:
在emacs的info手册中有专门一节讲fortran的, 也有与其他一些程序语言结合的章节, 里边有详细的介绍.
f77的续行: C-M-j, C-c C-d: 逆过程
怎样用粘贴从其他窗口拷贝的内容?
有时候从其他窗口拷贝的内容emacs并不认识, 粘贴不了. 这是因为内容是由几个缓冲区存放的, emacs有时找的不是主缓存, 所以粘贴不了或者粘贴的不是想要的. 有两个解决办法:
1. 在拷贝(或者选中有时也可看成拷贝, 但是在比如firefox中选中和拷贝的是放在两个地方的, 用Ctrl-V和鼠标中间输出的不一样, 这是好事)之后, 来到emacs窗口,
M-x clipboard-kill-region
M-x clipboad-yank
2. 用autocutsel 自动纠正emacs这种非X11的错误,
安装并 .xinitrc 中添加一行:
autocutsel &
要把它放在运行窗口管理器之前,否则它不会被运行!
3. 在X窗口中复制啊粘贴啊, 瞎折腾折腾, 有时侯emacs又可以象其他X窗口一样, 可以粘贴别处拷贝的内容了.
待解决:
想要帮定shift+方向键作为选定用, 这个组合键反正还没有用.
从emacs中往别处拷贝的汉字都是乱码, 怎么办? (暂时用kwrite打开拷贝)
怎样设置, 把win键拿来当M-用?
怎样设置使得自动加载flyspell-mode?
(等我载mozilla composer中编辑修改完准备退出的时候, 总有按C-x,C-s的冲动&.& )
在linuxsir上看到的, 先放这儿, 以后再整理:
选取好程序中的文本块后(可以用C-x h选取整个程序文本),按Esc C-\就会按默认的缩进样式排版该文本块。
可以打印一张refcard,一般常用的DD都搞定了!
这里是我常用的一些:
;; -----------------------------------------------------------------------------------------
;; Some useful commands:
;;
;; C-h w command - to check which key bind to the command
;; C-h k key - to check which command the key bind to
;; C-j - run the lisp command(put the cursor at end)
;;
;; C-c C-t - change mode to hungry-state and auto-state
;; C-c C-a - change mode to auto-state
;; C-c C-d - change mode to hungry-state
;; C-c C-e - expand macro
;; C-c C-\ - add '\' at then end of the line
;; C-u C-s - regular expression search
;; C-x 5 2 - open new frame
;; C-x 5 0 - close new frame
;;
;; M-; - insert a comment
;; M-\ - fixup whitespace
;; M-/ - auto complete the word
;; M-l - downcase-word
;;
;; Mark the region, then
;;
;; C-x r k - kill rectangle
;; C-x r t
我常用的快捷键:
C-x C-f :打开/新建文件
C-x S :保存所有缓冲区文件
C-x C-v:在当前缓冲区打开文件
C-x k :关闭当前缓冲区
C-x i : 在当前光标位置插入文件
M-x replace-string: 一次性替换字符串
M-x % : 循环替换。
C-s
C-r :查询
C-@ :设置标记,然后选取
C-w :相当于剪切。
M-w :相当于复制
C-y :粘贴
M-y : 循环粘贴。
C-o:开新行
C-f, C-b, C-p, C-n, M-f, M-b, C-v , M-v , C-l, M->, M-<移动。
C - !, 一次性执行shell, M-x shell, 启动shell外壳。
M-x compile:编译程序。
C-x m进入发邮件界面
C-c C-c 发送后离开
Esc x c++-mode,c-mode,python-mode....开始语言模式
C-x C-b列出缓冲区东东
呵呵,上面是我最常用的,
最初由 fog_proxy 发表
问一个问题,我emacs现在在Xwindow下用得很好,唯一的问题是显示的中文字体过大,不知道该如何把字体调小呢?以前也发贴请教过,不过仍然是没 有解决。
Emacs只能使用固定宽度的字体。
用xfontsel命令查看一下可用的字体列表。
然后在~/.Xdefaults或~/.Xresources里修改这一句如:
emacs.Font: *fixed-bold-r-*-14-*-*
订阅:
评论 (Atom)